Cumulus Basics Part VII - VXLAN routing - asymmetric IRB
In this post, we look at VXLAN routing with asymmetric IRB on Cumulus Linux.
Topology
We continue on with the same topology as the last post:
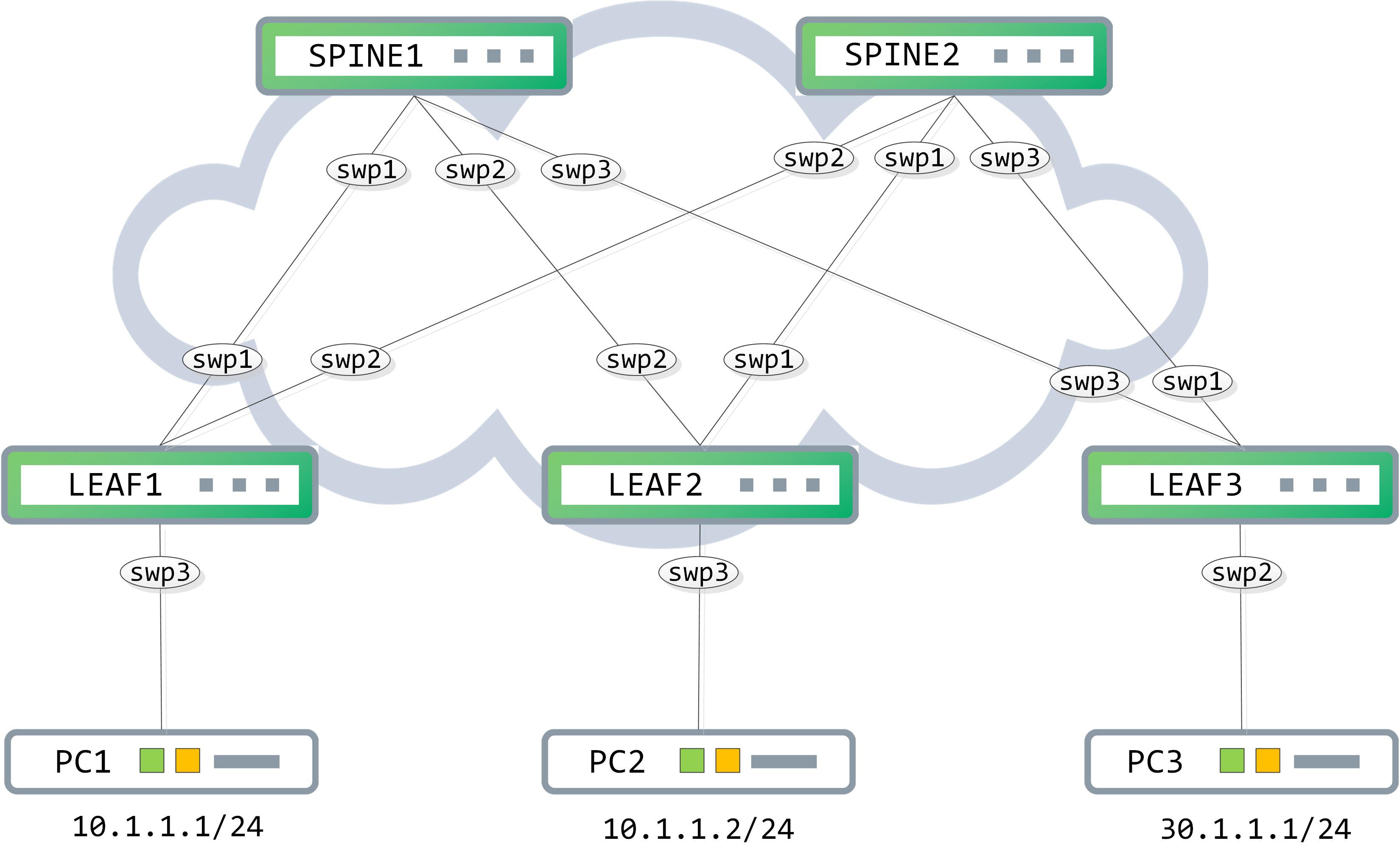
Our goal is to have PC1 talk to PC3 over the VXLAN fabric that we have built out. VXLAN routing can broadly be done using two methods - asymmetric and symmetric IRB. In this post, we will discuss the asymmetric methodology.
Understanding Asymmetric IRB
The logic behind asymmetric IRB is that the routing between VXLANs/VNIs is done at each LEAF. This is analogous to inter-VLAN routing where the routing from one VLAN to another happens on the first routed hop itself. To facilitate said inter-VLAN routing, you are required to have the L3 interfaces for both VLANs defined on the first hop (LEAF1 here, for example), so that the box is capable of taking in the packet from one VLAN, routing it into the other VLAN where it can then ARP for the end host directly.
Following the same logic, for inter-VXLAN routing, you are required to have the L3 interface for both VNIs on the first routed hop. Let’s break this down into chunks and start our configuration.
First, we need to have L3 interfaces for the VLANs themselves that will act as gateways for the end hosts:
// LEAF1
cumulus@LEAF1:~$ net add vlan 10 ip address 10.1.1.254/24
cumulus@LEAF1:~$ net add vlan 30 ip address 30.1.1.254/24
// LEAF3
cumulus@LEAF3:~$ net add vlan 10 ip address 10.1.1.254/24
cumulus@LEAF3:~$ net add vlan 30 ip address 30.1.1.254/24
Notice how the same IP address is defined at both LEAF switches for the same VLAN. Typically, what you should do here is define another virtual address with a virtual mac address common to all LEAF switches sharing this VLAN (VRR, in Cumulus terms). However, for simplicity sake, we are not doing that here.
Next, the routed interfaces for the corresponding VXLANs (or rather VNIs) are also created on both LEAF1 and LEAF3:
// LEAF1
// for VNI 10010, mapped to VLAN 10
cumulus@LEAF1:~$ net add vxlan vni10 vxlan id 10010
cumulus@LEAF1:~$ net add vxlan vni10 bridge access 10
cumulus@LEAF1:~$ net add vxlan vni10 vxlan local-tunnelip 1.1.1.1
// for VNI 10030, mapped to VLAN 30
cumulus@LEAF1:~$ net add vxlan vni30 vxlan id 10030
cumulus@LEAF1:~$ net add vxlan vni30 bridge access 30
cumulus@LEAF1:~$ net add vxlan vni30 vxlan local-tunnelip 1.1.1.1
// LEAF3
// for VNI 10010 mapped to VLAN 10
cumulus@LEAF3:~$ net add vxlan vni10 vxlan id 10010
cumulus@LEAF3:~$ net add vxlan vni10 bridge access 10
cumulus@LEAF3:~$ net add vxlan vni10 vxlan local-tunnelip 3.3.3.3
// for VNI 10030 mapped to VLAN 30
cumulus@LEAF3:~$ net add vxlan vni30 vxlan id 10030
cumulus@LEAF3:~$ net add vxlan vni30 bridge access 30
cumulus@LEAF3:~$ net add vxlan vni30 vxlan local-tunnelip 3.3.3.3
You can confirm the RD/RT values that are auto-generated for these VNIs using:
cumulus@LEAF1:~$ net show bgp evpn vni
Advertise Gateway Macip: Disabled
Advertise SVI Macip: Disabled
Advertise All VNI flag: Enabled
BUM flooding: Head-end replication
Number of L2 VNIs: 2
Number of L3 VNIs: 0
Flags: * - Kernel
VNI Type RD Import RT Export RT Tenant VRF
* 10030 L2 1.1.1.1:3 1:10030 1:10030 default
* 10010 L2 1.1.1.1:2 1:10010 1:10010 default
Remember, the default gateway of the hosts is the corresponding SVI IP address of the LEAF switch:
PC1> show ip
NAME : PC1[1]
IP/MASK : 10.1.1.1/24
GATEWAY : 10.1.1.254
DNS :
MAC : 00:50:79:66:68:06
LPORT : 20000
RHOST:PORT : 127.0.0.1:30000
MTU : 1500
PC3> show ip
NAME : PC3[1]
IP/MASK : 30.1.1.1/24
GATEWAY : 30.1.1.254
DNS :
MAC : 00:50:79:66:68:08
LPORT : 20000
RHOST:PORT : 127.0.0.1:30000
MTU : 1500
So, how does this all work?
The control-plane
PC1 initiates a ping. It first does an ‘and’ operation to determine if the destination is in the same subnet or not. In this case, it finds out that it is not, so it forwards the packet to its default gateway. In order to do this, it must first ARP for the default gateway, resolve that and then build the ICMP request packet.
This ARP request causes PC1s mac address to be learnt on swp3 of LEAF1. ‘Zebra’ notifies this to BGP; BGP adds this into its EVPN table and sends an update regarding this to its peers. This BGP update is carried to LEAF3, where BGP populates its EVPN table and then informs ‘Zebra’, which pushes this into the L2 table. This entire control-plane learning process can be visualized like so:
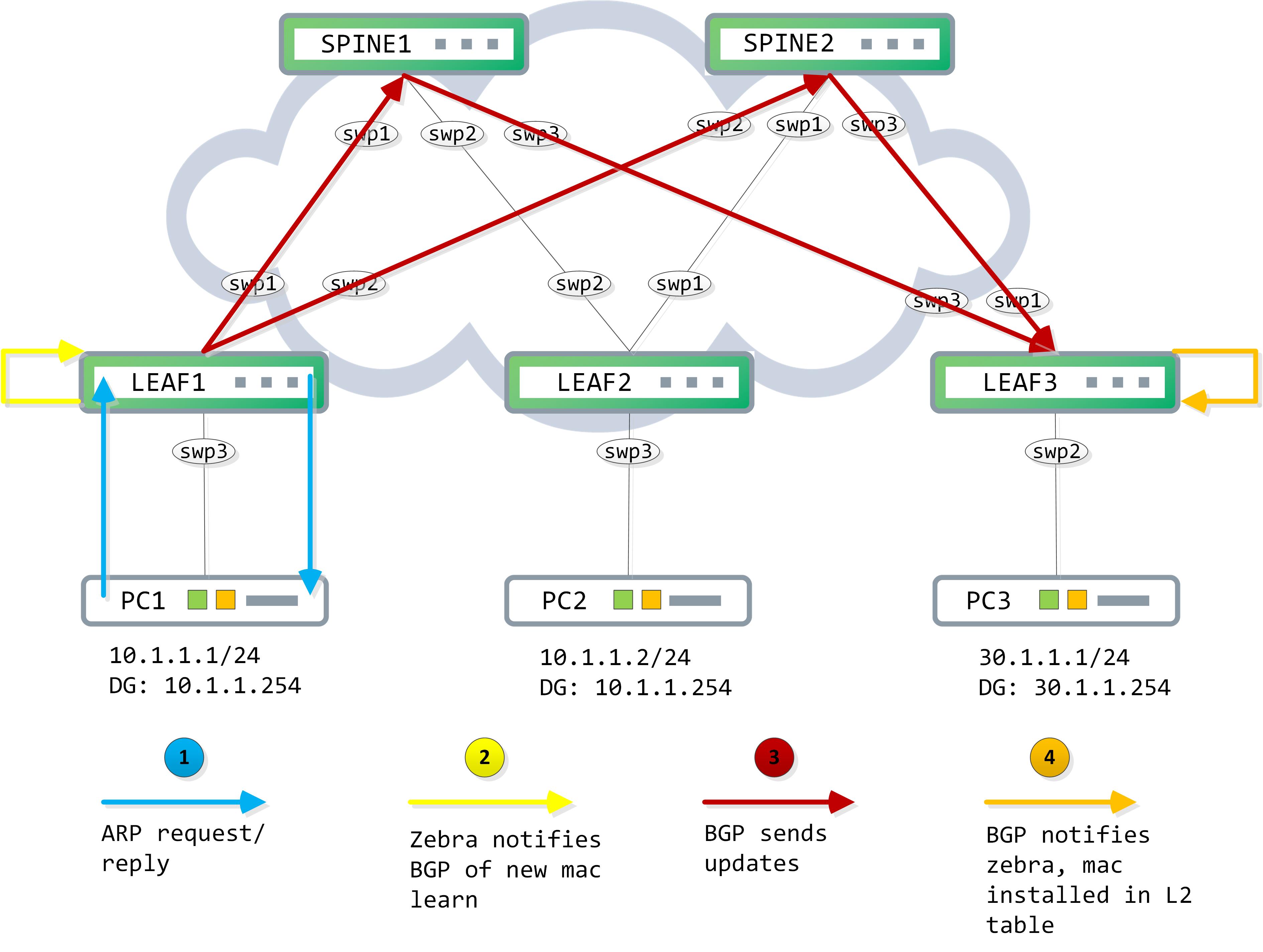
Debugs on the box can confirm this process. This is the first time we are introducing debugging on Cumulus boxes, so it’s good to make a note of this. Debugs are typically redirected to the ‘/var/log/frr/frr.log’ file but you need to set your logging level correctly first:
cumulus@LEAF3:~$ sudo vtysh
Hello, this is FRRouting (version 4.0+cl3u10).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
LEAF3# conf t
LEAF3(config)# log syslog debug
LEAF3(config)# end
‘sudo vtysh’ allows you to enter a Cisco IOS type prompt. From here, you set the syslog level to ‘debug’. This allows for debug logs to be logged in the /var/log/frr/frr.log file. Enable the relevant debugs now:
LEAF3# debug bgp updates
LEAF3# debug bgp zebra
LEAF3# debug zebra vxlan
LEAF3# debug zebra rib
LEAF3# debug zebra events
From the log file, I have taken relevant snippets of the debugs. On LEAF1, when PC1s mac address is first learnt:
// zebra processes mac and sends update to bgpd
2019-05-19T13:03:40.248233+00:00 LEAF1 zebra[865]: UPD MAC 00:50:79:66:68:06 intf swp3(5) VID 10 -> VNI 10010 curFlags 0x4
2019-05-19T13:03:40.249155+00:00 LEAF1 zebra[865]: Send MACIP Add flags 0x0 MAC 00:50:79:66:68:06 IP seq 0 L2-VNI 10010 to bgp
2019-05-19T13:03:40.250227+00:00 LEAF1 zebra[865]: Processing neighbors on local MAC 00:50:79:66:68:06 ADD, VNI 10010
2019-05-19T13:03:40.250601+00:00 LEAF1 zebra[865]: Send MACIP Add flags 0x0 MAC 00:50:79:66:68:06 IP 10.1.1.1 seq 0 L2-VNI 10010 to bgp
// bgpd receives this update and adds to its table
2019-05-19T13:03:40.250845+00:00 LEAF1 bgpd[874]: 0:Recv MACIP Add flags 0x0 MAC 00:50:79:66:68:06 IP VNI 10010 seq 0 state 0
2019-05-19T13:03:40.251222+00:00 LEAF1 bgpd[874]: 0:Recv MACIP Add flags 0x0 MAC 00:50:79:66:68:06 IP 10.1.1.1 VNI 10010 seq 0 state 0
2019-05-19T13:03:40.301259+00:00 LEAF1 bgpd[874]: group_announce_route_walkcb: afi=l2vpn, safi=evpn, p=[2]:[00:50:79:66:68:06]/224
2019-05-19T13:03:40.301930+00:00 LEAF1 bgpd[874]: subgroup_process_announce_selected: p=[2]:[00:50:79:66:68:06]/224, selected=0xaf8cac41e0
2019-05-19T13:03:40.302449+00:00 LEAF1 bgpd[874]: group_announce_route_walkcb: afi=l2vpn, safi=evpn, p=[2]:[00:50:79:66:68:06]:[10.1.1.1]/224
2019-05-19T13:03:40.302762+00:00 LEAF1 bgpd[874]: subgroup_process_announce_selected: p=[2]:[00:50:79:66:68:06]:[10.1.1.1]/224, selected=0xaf8cac3860
// bgp sends an update to its peers
2019-05-19T13:03:40.303018+00:00 LEAF1 bgpd[874]: u2:s2 send UPDATE w/ attr: nexthop 1.1.1.1, localpref 100, extcommunity ET:8 RT:1:10010, path
2019-05-19T13:03:40.303266+00:00 LEAF1 bgpd[874]: u2:s2 send MP_REACH for afi/safi 25/70
2019-05-19T13:03:40.303782+00:00 LEAF1 bgpd[874]: u2:s2 send UPDATE RD 1.1.1.1:2 [2]:[00:50:79:66:68:06]/224 label 10010 l2vpn evpn
2019-05-19T13:03:40.304096+00:00 LEAF1 bgpd[874]: u2:s2 send UPDATE RD 1.1.1.1:2 [2]:[00:50:79:66:68:06]:[10.1.1.1]/224 label 10010 l2vpn evpn
2019-05-19T13:03:40.304332+00:00 LEAF1 bgpd[874]: u2:s2 send UPDATE len 144 numpfx 2
2019-05-19T13:03:40.304744+00:00 LEAF1 bgpd[874]: u2:s2 swp1 send UPDATE w/ nexthop 1.1.1.1
2019-05-19T13:03:40.304961+00:00 LEAF1 bgpd[874]: u2:s2 swp2 send UPDATE w/ nexthop 1.1.1.1
Similar debugs from LEAF3, run in parallel:
// bgp on LEAF3 receives update from SPINE1
2019-05-19T13:03:40.017491+00:00 LEAF3 bgpd[887]: swp3 rcvd UPDATE w/ attr: nexthop 1.1.1.1, localpref 100, metric 0, extcommunity RT:1:10010 ET:8, originator 1.1.1.1, clusterlist 11.11.11.11, path
2019-05-19T13:03:40.017949+00:00 LEAF3 bgpd[887]: swp3 rcvd UPDATE wlen 0 attrlen 142 alen 0
2019-05-19T13:03:40.018244+00:00 LEAF3 bgpd[887]: swp3 rcvd RD 1.1.1.1:2 [2]:[00:50:79:66:68:06]/224 label 10010 l2vpn evpn
2019-05-19T13:03:40.018402+00:00 LEAF3 bgpd[887]: Tx ADD MACIP, VNI 10010 MAC 00:50:79:66:68:06 IP flags 0x0 seq 0 remote VTEP 1.1.1.1
2019-05-19T13:03:40.018523+00:00 LEAF3 bgpd[887]: swp3 rcvd RD 1.1.1.1:2 [2]:[00:50:79:66:68:06]:[10.1.1.1]/224 label 10010 l2vpn evpn
2019-05-19T13:03:40.018650+00:00 LEAF3 bgpd[887]: Tx ADD MACIP, VNI 10010 MAC 00:50:79:66:68:06 IP 10.1.1.1 flags 0x0 seq 0 remote VTEP 1.1.1.1
// bgpd informs zebra, which installs the mac address
2019-05-19T13:03:40.021415+00:00 LEAF3 zebra[880]: zebra message comes from socket [16]
2019-05-19T13:03:40.021681+00:00 LEAF3 zebra[880]: Recv MACIP ADD VNI 10010 MAC 00:50:79:66:68:06 flags 0x0 seq 0 VTEP 1.1.1.1 from bgp
2019-05-19T13:03:40.021893+00:00 LEAF3 zebra[880]: Processing neighbors on remote MAC 00:50:79:66:68:06 ADD, VNI 10010
2019-05-19T13:03:40.022072+00:00 LEAF3 zebra[880]: zebra message comes from socket [16]
2019-05-19T13:03:40.022363+00:00 LEAF3 zebra[880]: Recv MACIP ADD VNI 10010 MAC 00:50:79:66:68:06 IP 10.1.1.1 flags 0x0 seq 0 VTEP 1.1.1.1 from bgp
You can now look at the BGP EVPN table to confirm what was installed:
// LEAF1
cumulus@LEAF1:~$ net show bgp evpn route
BGP table version is 1, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal
Origin codes: i - IGP, e - EGP, ? - incomplete
EVPN type-2 prefix: [2]:[ESI]:[EthTag]:[MAClen]:[MAC]:[IPlen]:[IP]
EVPN type-3 prefix: [3]:[EthTag]:[IPlen]:[OrigIP]
EVPN type-5 prefix: [5]:[ESI]:[EthTag]:[IPlen]:[IP]
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 1.1.1.1:2
*> [3]:[0]:[32]:[1.1.1.1]
1.1.1.1 32768 i
Route Distinguisher: 1.1.1.1:3
*> [2]:[0]:[0]:[48]:[00:50:79:66:68:06]
1.1.1.1 32768 i
*> [2]:[0]:[0]:[48]:[00:50:79:66:68:06]:[32]:[10.1.1.1]
1.1.1.1 32768 i
*> [3]:[0]:[32]:[1.1.1.1]
1.1.1.1 32768 i
Route Distinguisher: 2.2.2.2:2
* i[3]:[0]:[32]:[2.2.2.2]
2.2.2.2 0 100 0 i
*>i[3]:[0]:[32]:[2.2.2.2]
2.2.2.2 0 100 0 i
Route Distinguisher: 3.3.3.3:2
* i[2]:[0]:[0]:[48]:[00:50:79:66:68:08]
3.3.3.3 0 100 0 i
*>i[2]:[0]:[0]:[48]:[00:50:79:66:68:08]
3.3.3.3 0 100 0 i
* i[2]:[0]:[0]:[48]:[00:50:79:66:68:08]:[32]:[30.1.1.1]
3.3.3.3 0 100 0 i
*>i[2]:[0]:[0]:[48]:[00:50:79:66:68:08]:[32]:[30.1.1.1]
3.3.3.3 0 100 0 i
* i[3]:[0]:[32]:[3.3.3.3]
3.3.3.3 0 100 0 i
*>i[3]:[0]:[32]:[3.3.3.3]
3.3.3.3 0 100 0 i
Route Distinguisher: 3.3.3.3:3
* i[3]:[0]:[32]:[3.3.3.3]
3.3.3.3 0 100 0 i
*>i[3]:[0]:[32]:[3.3.3.3]
3.3.3.3 0 100 0 i
Displayed 9 prefixes (14 paths)
// LEAF3
cumulus@LEAF3:~$ net show bgp evpn route
BGP table version is 1, local router ID is 3.3.3.3
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal
Origin codes: i - IGP, e - EGP, ? - incomplete
EVPN type-2 prefix: [2]:[ESI]:[EthTag]:[MAClen]:[MAC]:[IPlen]:[IP]
EVPN type-3 prefix: [3]:[EthTag]:[IPlen]:[OrigIP]
EVPN type-5 prefix: [5]:[ESI]:[EthTag]:[IPlen]:[IP]
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 1.1.1.1:2
* i[3]:[0]:[32]:[1.1.1.1]
1.1.1.1 0 100 0 i
*>i[3]:[0]:[32]:[1.1.1.1]
1.1.1.1 0 100 0 i
Route Distinguisher: 1.1.1.1:3
* i[2]:[0]:[0]:[48]:[00:50:79:66:68:06]
1.1.1.1 0 100 0 i
*>i[2]:[0]:[0]:[48]:[00:50:79:66:68:06]
1.1.1.1 0 100 0 i
* i[2]:[0]:[0]:[48]:[00:50:79:66:68:06]:[32]:[10.1.1.1]
1.1.1.1 0 100 0 i
*>i[2]:[0]:[0]:[48]:[00:50:79:66:68:06]:[32]:[10.1.1.1]
1.1.1.1 0 100 0 i
* i[3]:[0]:[32]:[1.1.1.1]
1.1.1.1 0 100 0 i
*>i[3]:[0]:[32]:[1.1.1.1]
1.1.1.1 0 100 0 i
Route Distinguisher: 2.2.2.2:2
* i[3]:[0]:[32]:[2.2.2.2]
2.2.2.2 0 100 0 i
*>i[3]:[0]:[32]:[2.2.2.2]
2.2.2.2 0 100 0 i
Route Distinguisher: 3.3.3.3:2
*> [2]:[0]:[0]:[48]:[00:50:79:66:68:08]
3.3.3.3 32768 i
*> [2]:[0]:[0]:[48]:[00:50:79:66:68:08]:[32]:[30.1.1.1]
3.3.3.3 32768 i
*> [3]:[0]:[32]:[3.3.3.3]
3.3.3.3 32768 i
Route Distinguisher: 3.3.3.3:3
*> [3]:[0]:[32]:[3.3.3.3]
3.3.3.3 32768 i
Displayed 9 prefixes (14 paths)
Also confirm the entries in the mac address table, which should now include the mac address of the the host learnt via BGP EVPN:
// LEAF1
cumulus@LEAF1:~$ net show bridge macs 00:50:79:66:68:08
VLAN Master Interface MAC TunnelDest State Flags LastSeen
-------- ------ --------- ----------------- ---------- ----- ------------- --------
30 bridge vni30 00:50:79:66:68:08 offload 00:00:26
untagged vni30 00:50:79:66:68:08 3.3.3.3 self, offload 00:10:48
// LEAF3
cumulus@LEAF3:~$ net show bridge macs 00:50:79:66:68:06
VLAN Master Interface MAC TunnelDest State Flags LastSeen
-------- ------ --------- ----------------- ---------- ----- ------------- --------
10 bridge vni10 00:50:79:66:68:06 offload 00:11:02
untagged vni10 00:50:79:66:68:06 1.1.1.1 self, offload 00:11:02
Remember that the presence of the mac address in the BGP EVPN table is purely controlled by the presence of the same mac address in the L2 table. When the mac is added to the L2 table, a notification is sent to BGP to add it to its EVPN table and advertise the NLRI. The mac address is subjected to its normal mac ageing timers in the L2 table - if/when the mac expires and it gets deleted from the L2 table, again, BGP is notified of the same and it sends a withdraw message for that mac address.
This concludes the workings of the control-plane.
The data-plane
Once PC1 resolves its default gateway, it generates the native ICMP packet. LEAF1 gets this:
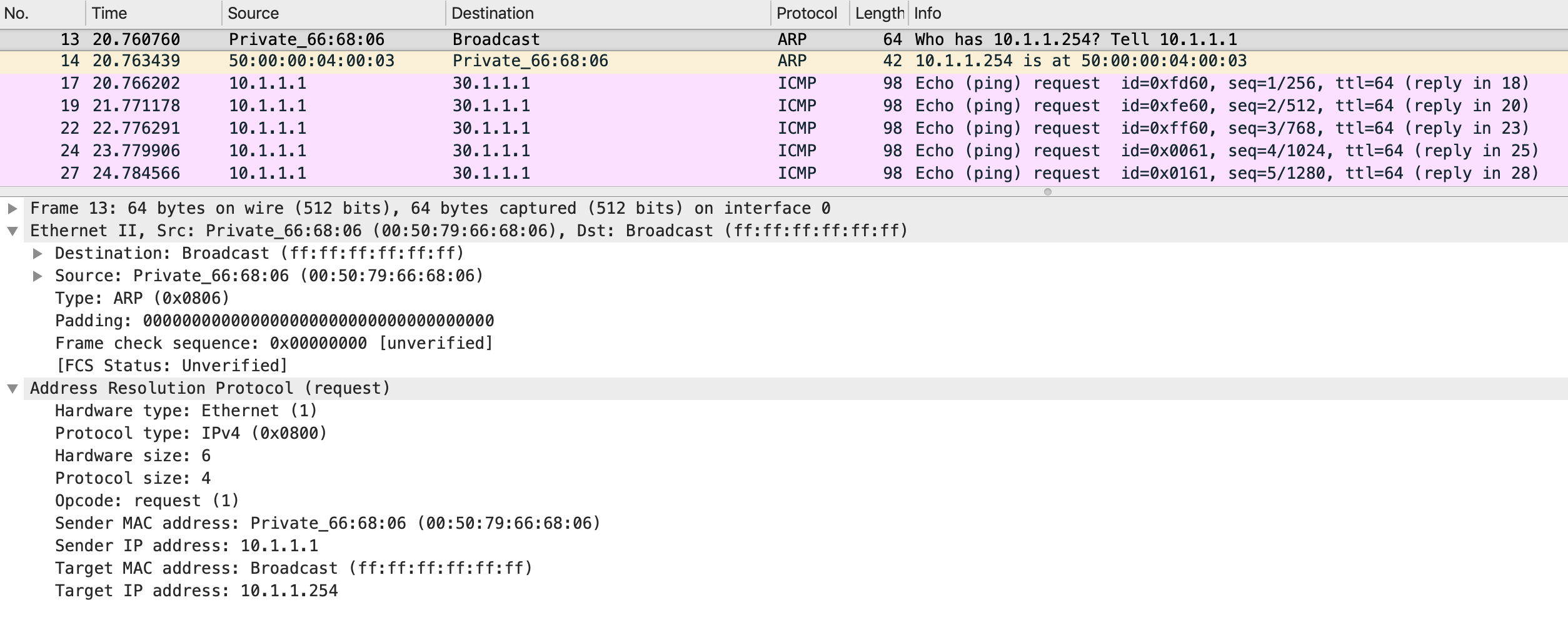
Since the destination mac address is of LEAF1, it strips off the Ethernet header and does a route lookup on the destination IP address in the IP header.
cumulus@LEAF1:~$ net show route 30.1.1.1
RIB entry for 30.1.1.1
======================
Routing entry for 30.1.1.0/24
Known via "connected", distance 0, metric 0, best
Last update 00:10:17 ago
* directly connected, vlan30
FIB entry for 30.1.1.1
======================
30.1.1.0/24 dev vlan30 proto kernel scope link src 30.1.1.254
The destination is directly connected, so LEAF1 can ARP for it. Here’s where things get a bit interesting - if you take a packet capture, you would see no ARPs generated. This is because of an enhancement that reduces flooding within the VXLAN fabric (called ARP suppression). These VTEPs (VXLAN tunnel endpoints) maintain an arp-cache that can be populated via a type-2 mac+ip route. This local ARP cache can be used to proxy ARP (note - this is supposed to be disabled by default and enabled using the command ‘net add vxlan bridge arp-nd-suppress on’ but the behavior on 3.7.5 appears to indicate that it is enabled by default).
You can confirm what is there in the arp-cache using the following command:
// LEAF1
cumulus@LEAF1:~$ net show evpn arp-cache vni all
VNI 10030 #ARP (IPv4 and IPv6, local and remote) 3
IP Type State MAC Remote VTEP
30.1.1.1 remote active 00:50:79:66:68:08 3.3.3.3
fe80::5200:ff:fe04:3 local active 50:00:00:04:00:03
30.1.1.254 local active 50:00:00:04:00:03
VNI 10010 #ARP (IPv4 and IPv6, local and remote) 3
IP Type State MAC Remote VTEP
10.1.1.254 local active 50:00:00:04:00:03
10.1.1.1 local active 00:50:79:66:68:06
fe80::5200:ff:fe04:3 local active 50:00:00:04:00:03
// LEAF3
cumulus@LEAF3:~$ net show evpn arp-cache vni all
VNI 10030 #ARP (IPv4 and IPv6, local and remote) 3
IP Type State MAC Remote VTEP
fe80::5200:ff:fe03:2 local active 50:00:00:03:00:02
30.1.1.1 local active 00:50:79:66:68:08
30.1.1.254 local active 50:00:00:03:00:02
VNI 10010 #ARP (IPv4 and IPv6, local and remote) 3
IP Type State MAC Remote VTEP
10.1.1.254 local active 50:00:00:03:00:02
fe80::5200:ff:fe03:2 local active 50:00:00:03:00:02
10.1.1.1 remote active 00:50:79:66:68:06 1.1.1.1
LEAF1 has all the required information to forward this packet. It encapsulates this with the relevant headers and forwards the packet. Assuming that the link to SPINE1 is chosen as the hash, the following packet is sent:
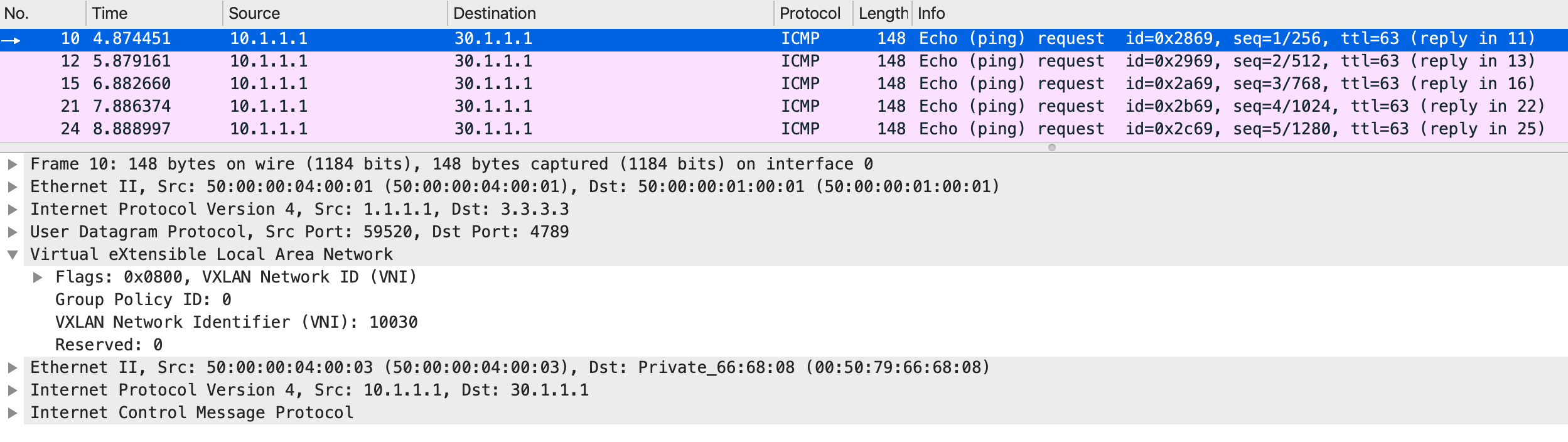
The VXLAN header contains the egress VNI - 10030 in this case. The outer IP header has a source IP address of the VTEP encapsulating the packet (1.1.1.1, in this case) and a destination IP address of the peer VTEP (3.3.3.3, in this case).
Assuming SPINE1 gets it, it simply does a route lookup for the destination (since the destination mac address belongs to itself):
cumulus@SPINE1:~$ net show route 3.3.3.3
RIB entry for 3.3.3.3
=====================
Routing entry for 3.3.3.3/32
Known via "bgp", distance 200, metric 0, best
Last update 02:28:05 ago
* fe80::5200:ff:fe03:3, via swp3
FIB entry for 3.3.3.3
=====================
3.3.3.3 via 169.254.0.1 dev swp3 proto bgp metric 20 onlink
It rewrites the layer2 header and forwards the packet to LEAF3. LEAF3 decapsulates it and forwards the native ICMP packet to PC3. The data-plane process can be visualized like so:
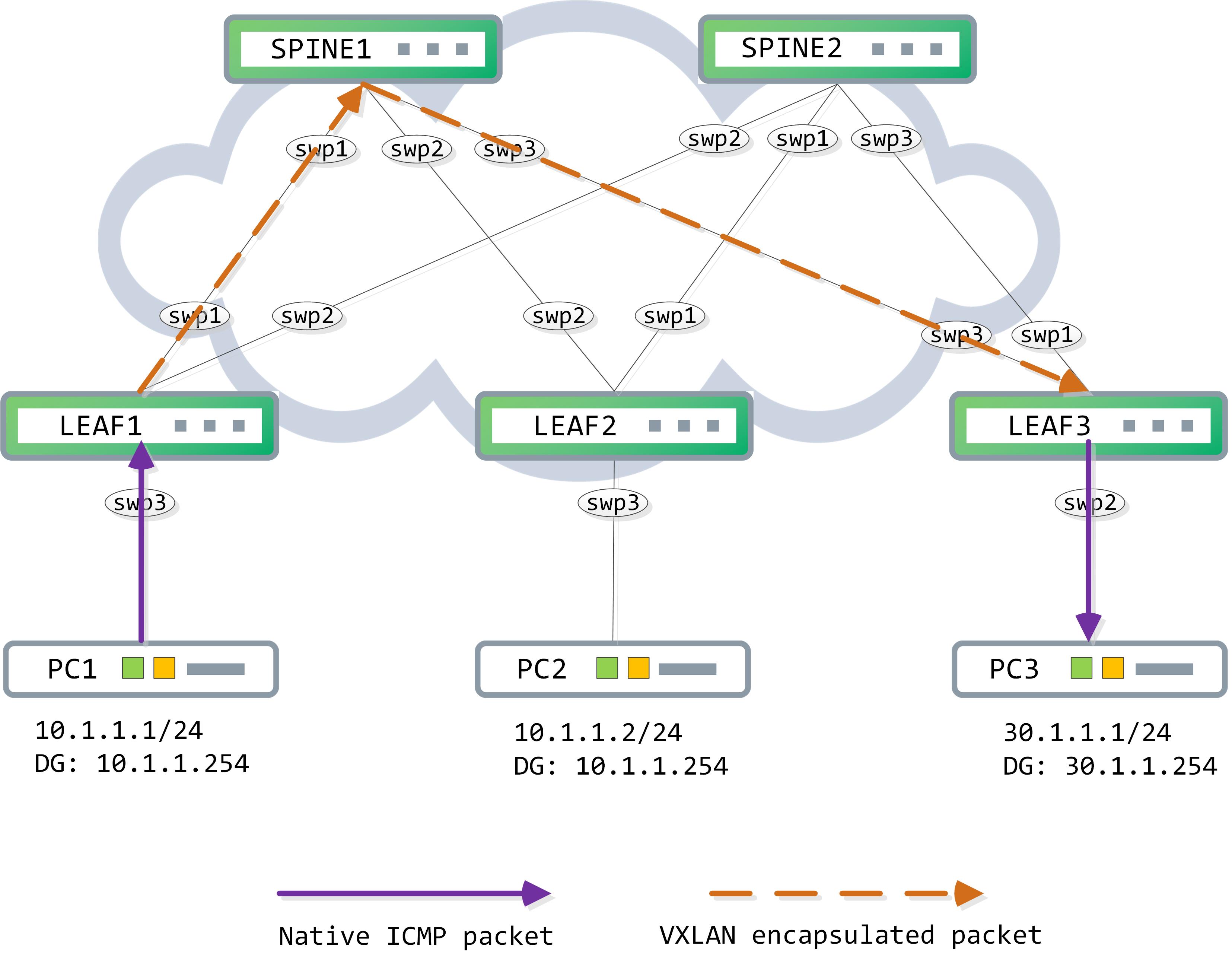
The same process happens backwards from PC3 to PC1 now. The egress VNI (once LEAF3 encapsulates the ICMP reply) would be 10010 in this case. The return packet from LEAF3 is this:
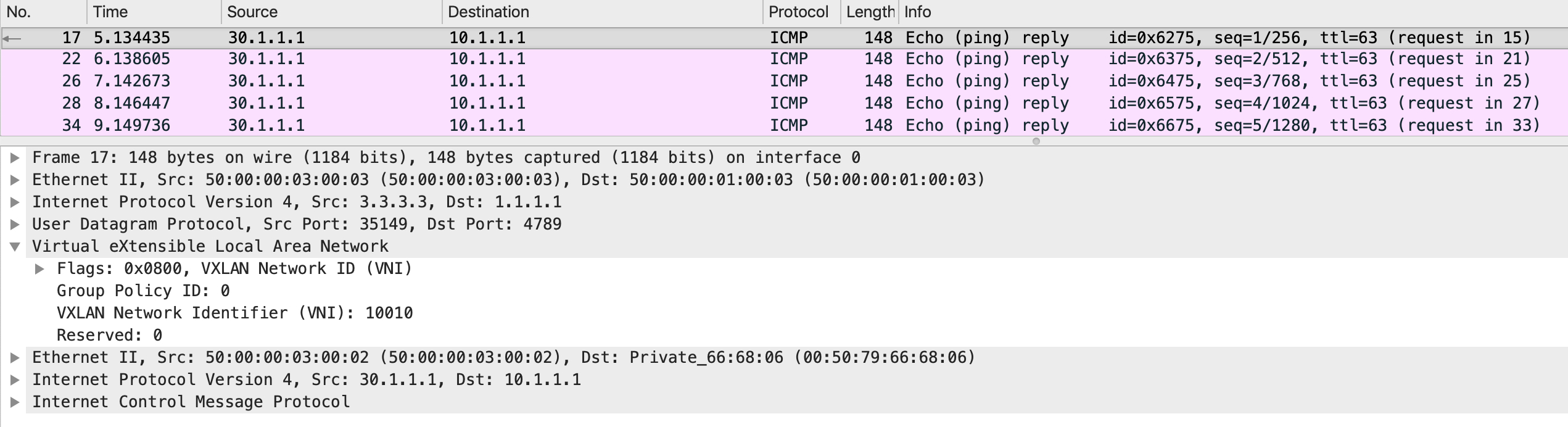
This has been fun, hasn’t it? We looked at the basic workflows for both data-plane and control-plane of an asymmetric IRB based VXLAN fabric and successfully routed traffic between VNIs 10010 and 10030.