Cumulus Part X - VXLAN EVPN and MLAG
In this post, we take a look at the interaction of MLAG with an EVPN based VXLAN fabric on Cumulus Linux.
Introduction
MLAG or MC-LAG (multi-chassis link aggregation) is a fairly common deployment model at the access/leaf layer of both Enterprise and Data Center networks, typically offered by most leading vendors (with different terminologies - vPC, VSS, stackwise-virtual and so on).
The general idea is to offer redundancy at the access layer by pairing together two access/leaf switches into a common logical switch, from the perspective of any devices downstream. Details of Cumulus' implementation can be found here.
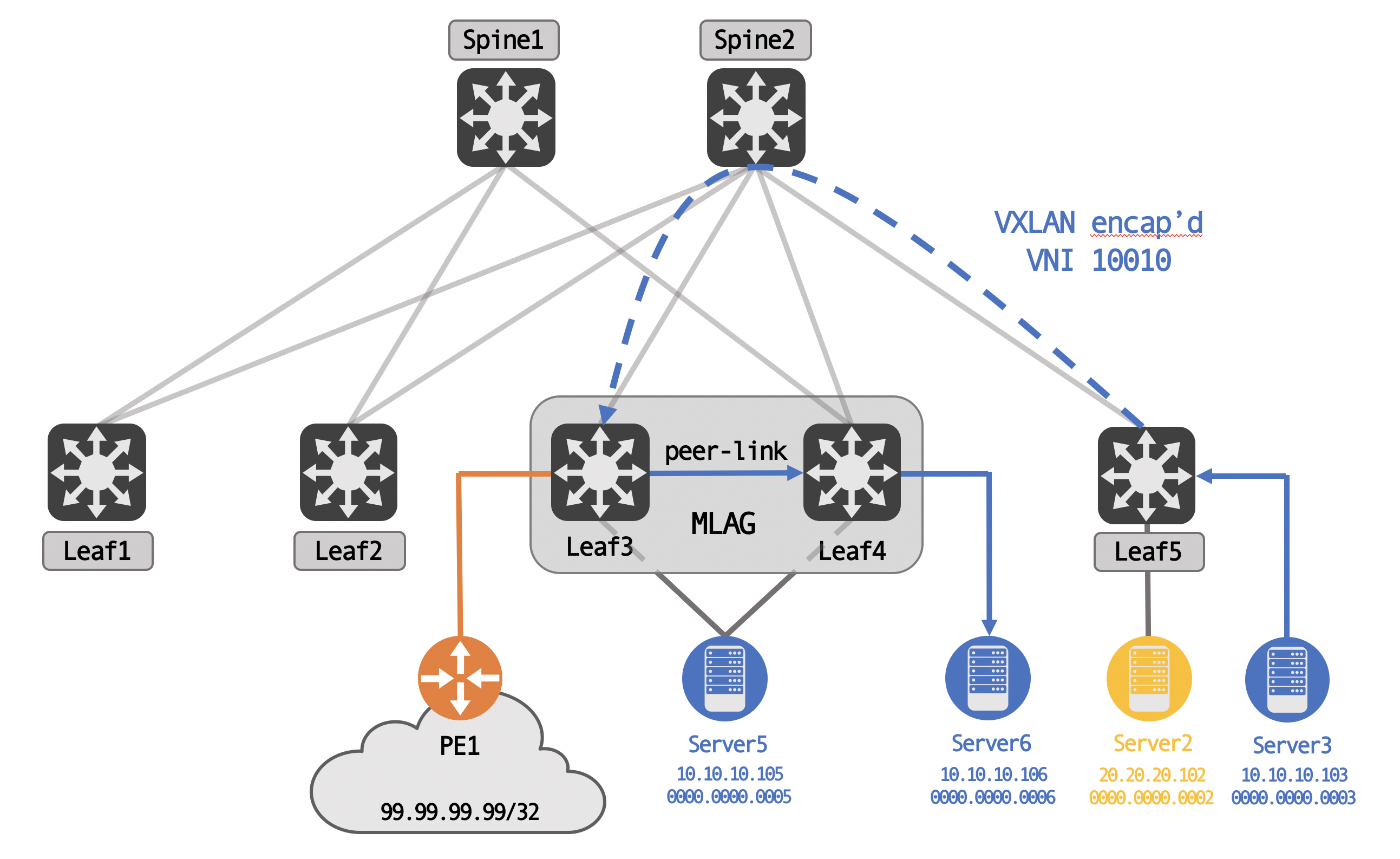
Topology
For this post, we’re going to be using the following topology (tested with Cumulus VX 4.2):
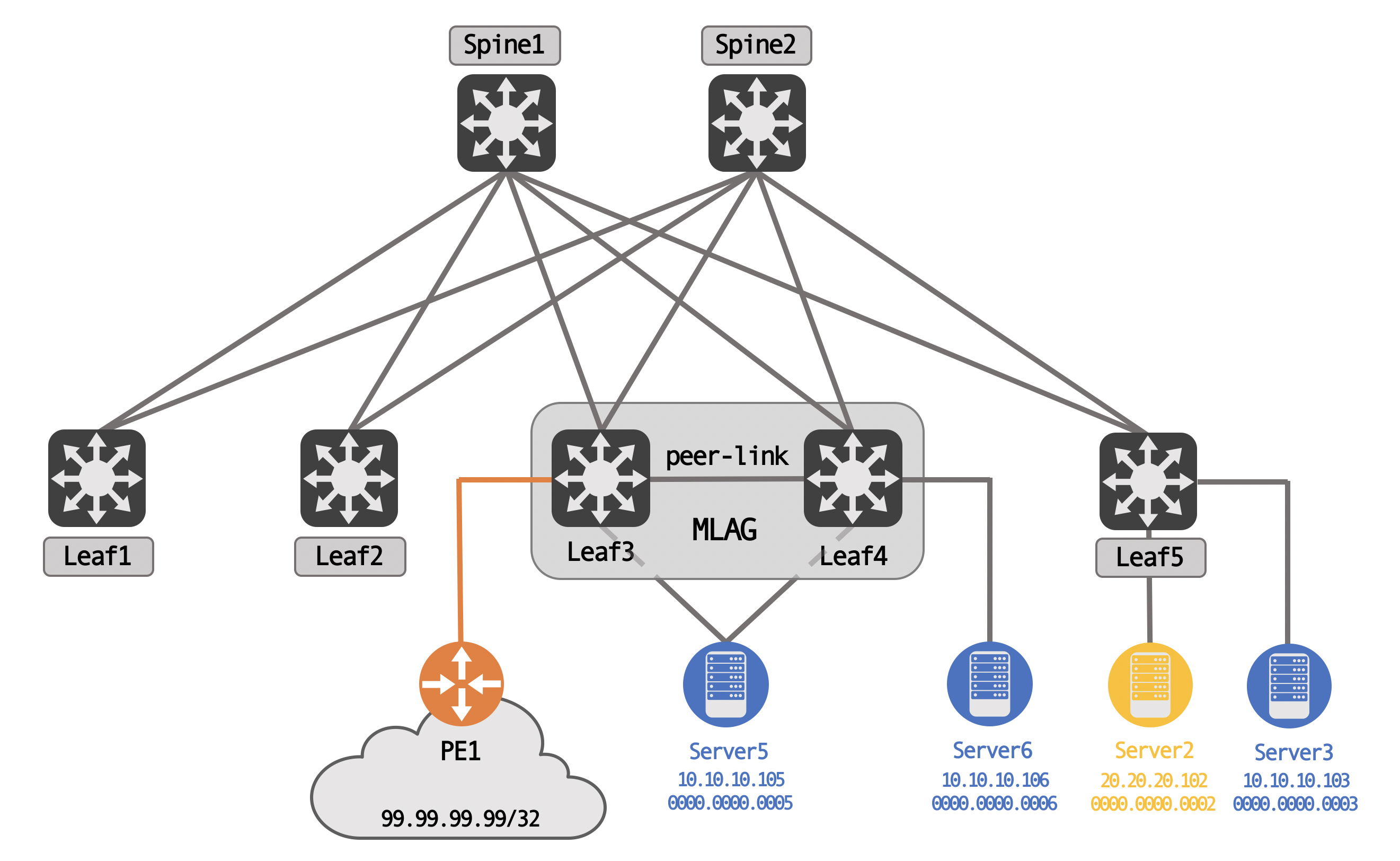
We have three servers, Server5, Server6 and Server3 in VLAN 10, with another server, Server2, in VLAN 20. Server5 is uplinked to both MLAG peers, while Server6 is an orphan device, off of Leaf4 only.
We also have external connectivity via PE1, again, connected only to one of the MLAG peers - Leaf3, in this case. PE1 is advertising 99.99.99.99/32, an external network, to Leaf3.
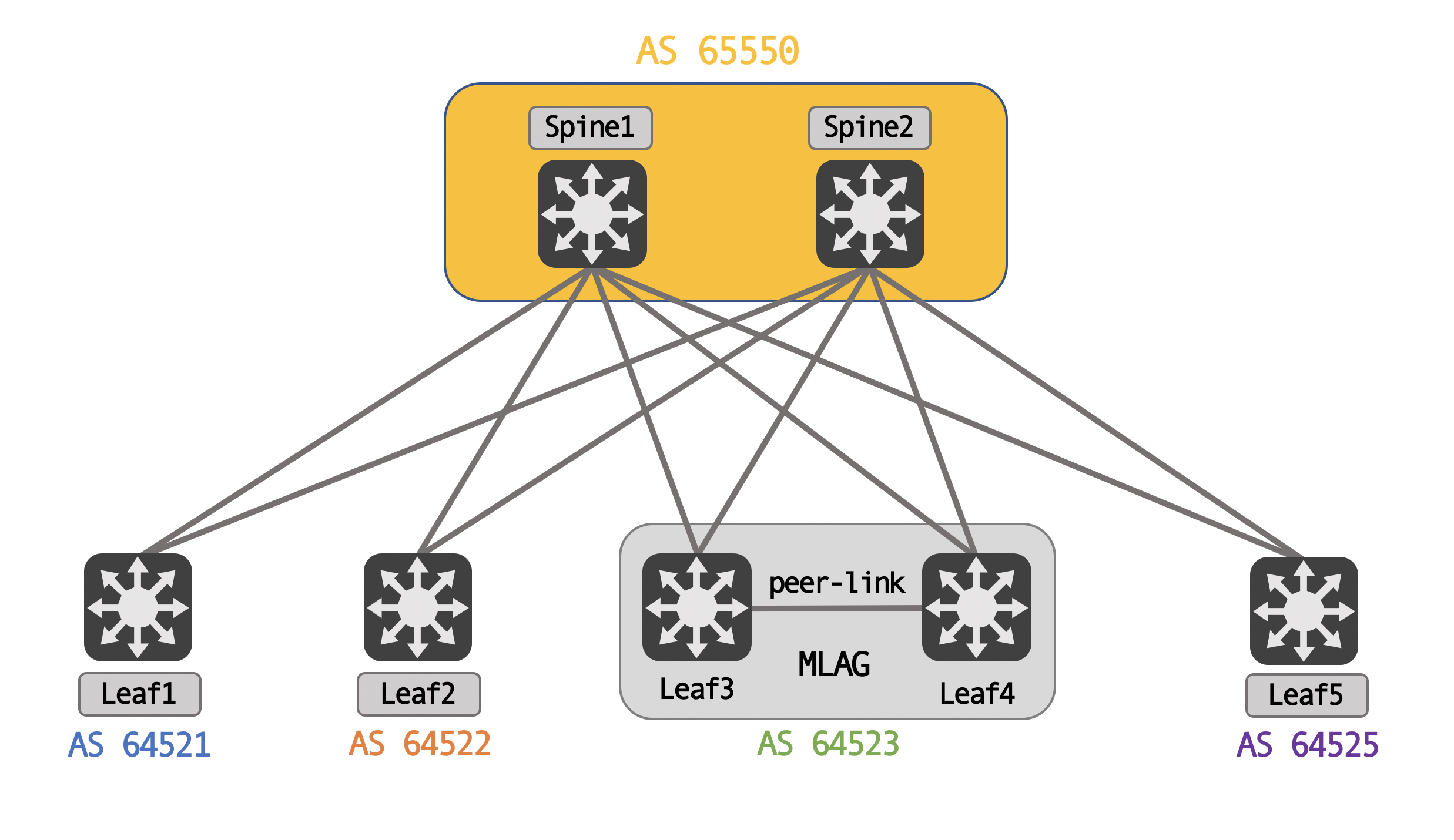
Logically, for BGP peering, the spines share a common AS, while each leaf is it’s own unique AS. This is a standard eBGP type design, meant to avoid BGP path hunting issues.
Basic configuration
Each of these devices have a loopback configured. For the leaf’s, these loopbacks are the VTEP IPs. The MLAG pair have unique loopacks, but also an anycast CLAG VTEP IP that is configured (similar to a secondary IP):
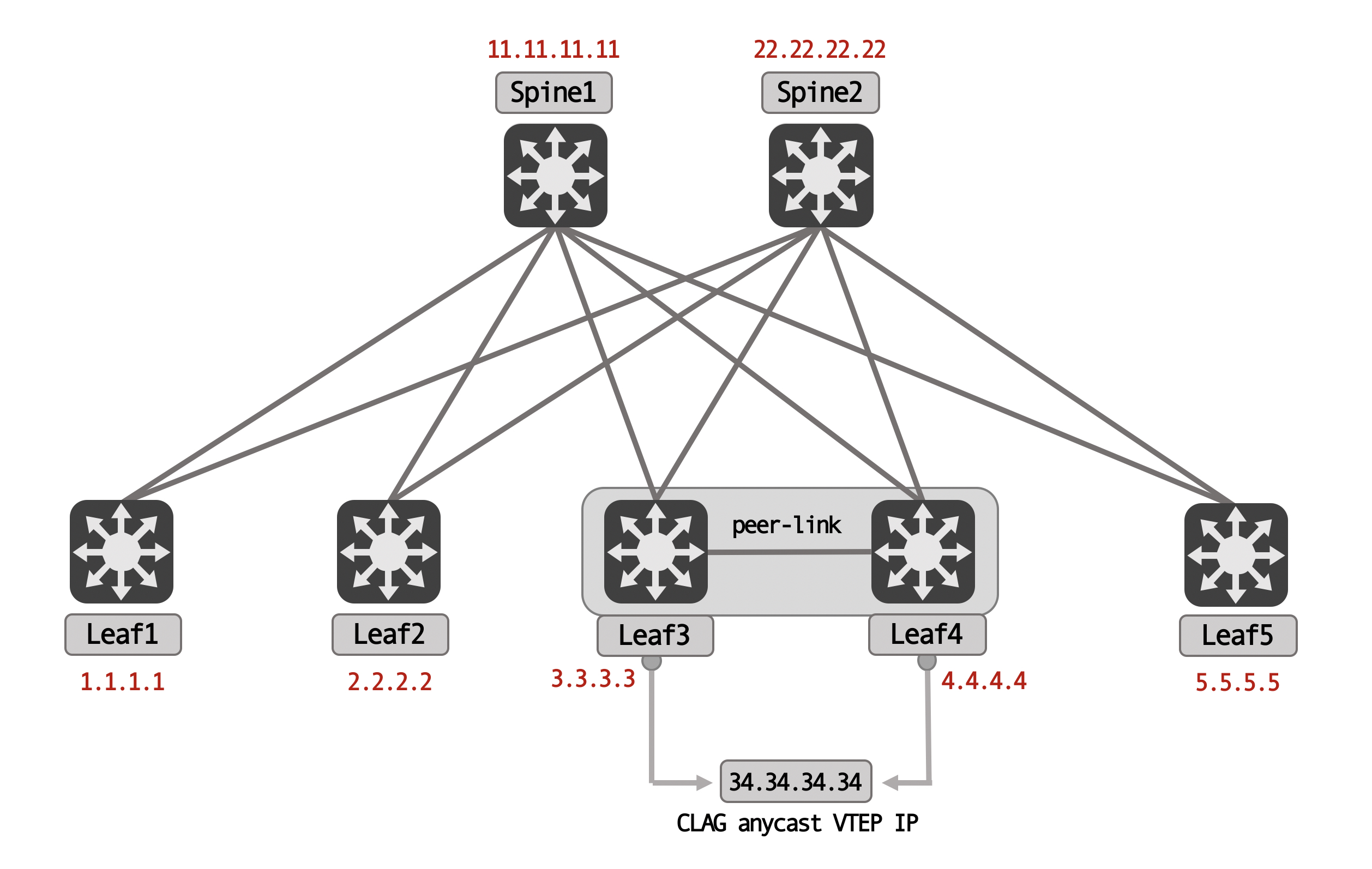
This CLAG anycast IP is configured under the loopback itself, for both Leaf3 and Leaf4:
// Leaf3
cumulus@Leaf3:mgmt:~$ net show configuration interface lo
interface lo
# The primary network interface
address 3.3.3.3/32
clagd-vxlan-anycast-ip 34.34.34.34
vxlan-local-tunnelip 3.3.3.3
// Leaf4
cumulus@Leaf4:mgmt:~$ net show configuration interface lo
interface lo
# The primary network interface
address 4.4.4.4/32
clagd-vxlan-anycast-ip 34.34.34.34
vxlan-local-tunnelip 4.4.4.4
Each of the MLAG peers form an eBGP peering with the spines, and an iBGP peering with each other. This iBGP peering is important for failure conditions (we’ll look at this in a little bit).
// IPv4 unicast peering
cumulus@Leaf3:mgmt:~$ net show bgp ipv4 unicast summary
BGP router identifier 3.3.3.3, local AS number 64523 vrf-id 0
BGP table version 26
RIB entries 11, using 2112 bytes of memory
Peers 3, using 64 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
Leaf4(peerlink.4094) 4 64523 87384 87976 0 0 0 07:26:27 5
Spine1(swp1) 4 65550 87974 87971 0 0 0 07:34:50 3
Spine2(swp2) 4 65550 87973 87968 0 0 0 07:34:50 3
Total number of neighbors 3
// L2VPN EVPN unicast peering
cumulus@Leaf3:mgmt:~$ net show bgp l2vpn evpn summary
BGP router identifier 3.3.3.3, local AS number 64523 vrf-id 0
BGP table version 0
RIB entries 25, using 4800 bytes of memory
Peers 3, using 64 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
Leaf4(peerlink.4094) 4 64523 87387 87979 0 0 0 07:26:37 30
Spine1(swp1) 4 65550 87977 87974 0 0 0 07:35:00 30
Spine2(swp2) 4 65550 87976 87971 0 0 0 07:35:00 30
Total number of neighbors 3
Control-plane learning with MLAG
When a MAC address is learnt over the MLAG, it is synced to the MLAG peer as well. Both the peers would insert the entry in their BGP EVPN tables and advertise it out. As an example, Server5s MAC address is learnt by both Leaf3 and Leaf4 and advertised via BGP EVPN to the spines and to each other, over the iBGP peering.
// Leaf3
cumulus@Leaf3:mgmt:~$ net show bridge macs 00:00:00:00:00:05
VLAN Master Interface MAC TunnelDest State Flags LastSeen
---- ------ ------------ ----------------- ---------- ----- ----- --------
10 bridge bond-server5 00:00:00:00:00:05 00:01:03
cumulus@Leaf3:mgmt:~$ net show bgp l2vpn evpn route rd 3.3.3.3:2 mac 00:00:00:00:00:05
BGP routing table entry for 3.3.3.3:2:[2]:[0]:[48]:[00:00:00:00:00:05]
Paths: (1 available, best #1)
Advertised to non peer-group peers:
Leaf4(peerlink.4094) Spine1(swp1) Spine2(swp2)
Route [2]:[0]:[48]:[00:00:00:00:00:05] VNI 10010/10040
Local
34.34.34.34 from 0.0.0.0 (3.3.3.3)
Origin IGP, weight 32768, valid, sourced, local, bestpath-from-AS Local, best (First path received)
Extended Community: ET:8 RT:3:10010 RT:3:10040 Rmac:44:38:39:ff:00:05 MM:1
Last update: Wed Aug 4 06:28:11 2021
// Leaf4
cumulus@Leaf4:mgmt:~$ net show bridge macs 00:00:00:00:00:05
VLAN Master Interface MAC TunnelDest State Flags LastSeen
---- ------ ------------ ----------------- ---------- ----- ----- --------
10 bridge bond-server5 00:00:00:00:00:05 00:00:11
cumulus@Leaf4:mgmt:~$ net show bgp l2vpn evpn route rd 4.4.4.4:3 mac 00:00:00:00:00:05
BGP routing table entry for 4.4.4.4:3:[2]:[0]:[48]:[00:00:00:00:00:05]
Paths: (1 available, best #1)
Advertised to non peer-group peers:
Leaf3(peerlink.4094) Spine1(swp1) Spine2(swp2)
Route [2]:[0]:[48]:[00:00:00:00:00:05] VNI 10010/10040
Local
34.34.34.34 from 0.0.0.0 (4.4.4.4)
Origin IGP, weight 32768, valid, sourced, local, bestpath-from-AS Local, best (First path received)
Extended Community: ET:8 RT:4:10010 RT:4:10040 Rmac:44:38:39:ff:00:05
Last update: Wed Aug 4 12:17:01 2021
There are two big things to remember with MLAG and BGP EVPN advertisements:
-
Type-2 EVPN prefixes are sent using the anycast VTEP IP address as the next-hop.
-
Type-5 EVPN prefixes are sent using the local VTEP IP address (default behavior in Cumulus Linux, other vendors provide a knob to optionally enable it).
The first big why - why do we need an anycast VTEP IP address for the MLAG peers? This just allows for easy BGP filtering - remember, when Leaf3 advertises a prefix into BGP EVPN, it adds it’s own AS number, since the update is being sent to eBGP peers (Spine1/Spine2). When Leaf4 gets this, the update is denied because it sees it’s own AS - basic BGP loop prevention.
However, this doesn’t apply to the iBGP peering that is created over the peer-link. This is where the anycast VTEP IP is useful - because the next-hop is owned by the peers, they will drop any BGP NLRI which has this next-hop (due to self next-hop/martian check). This is important because we wouldn’t want the MLAG peers to see each other as next hops (over VXLAN) for locally attached hosts.
With a simple BGP updates debug, you can confirm that the peers drop this because of the self next-hop check:
Leaf4 bgpd[895]: peerlink.4094 rcvd UPDATE w/ attr: nexthop 34.34.34.34,
localpref 100, extcommunity RT:3:10010 RT:3:10040 ET:8 MM:1 Rmac:44:38:39:ff:00:05, path
Leaf4 bgpd[895]: peerlink.4094 rcvd UPDATE about RD 3.3.3.3:2
[2]:[00:00:00:00:00:05]/320 label 10010
l2vpn evpn -- DENIED due to: martian or self next-hop;
Leaf4 bgpd[895]: peerlink.4094 rcvd UPDATE about RD 3.3.3.3:2
[2]:[00:00:00:00:00:05]:[10.10.10.105]/320 label 10010/10040
l2vpn evpn -- DENIED due to: martian or self next-hop;
Remember, even orphan devices are sent with this anycast VTEP address. For example, in our case, Server6 is an orphan device. Leaf4 sends the BGP EVPN update with the anycast VTEP address:
cumulus@Leaf4:mgmt:~$ net show bgp l2vpn evpn route rd 4.4.4.4:3 mac 00:00:00:00:00:06 ip 10.10.10.106
BGP routing table entry for 4.4.4.4:3:[2]:[0]:[48]:[00:00:00:00:00:06]:[32]:[10.10.10.106]
Paths: (1 available, best #1)
Advertised to non peer-group peers:
Leaf3(peerlink.4094) Spine1(swp1) Spine2(swp2)
Route [2]:[0]:[48]:[00:00:00:00:00:06]:[32]:[10.10.10.106] VNI 10010/10040
Local
34.34.34.34 from 0.0.0.0 (4.4.4.4)
Origin IGP, weight 32768, valid, sourced, local, bestpath-from-AS Local, best (First path received)
Extended Community: ET:8 RT:4:10010 RT:4:10040 Rmac:44:38:39:ff:00:05
Last update: Wed Aug 4 12:17:01 2021
On remote VTEPs (taking Leaf5, as an example), this is installed with 34.34.34.34 as the next-hop:
// BGP table
cumulus@Leaf5:mgmt:~$ net show bgp l2vpn evpn route rd 4.4.4.4:3 mac 00:00:00:00:00:06 ip 10.10.10.106
BGP routing table entry for 4.4.4.4:3:[2]:[00:00:00:00:00:06]:[10.10.10.106]/352
Paths: (2 available, best #2)
Advertised to non peer-group peers:
Spine1(swp1) Spine2(swp2)
Route [2]:[0]:[48]:[00:00:00:00:00:06]:[32]:[10.10.10.106] VNI 10010/10040
65550 64523
34.34.34.34 from Spine2(swp2) (22.22.22.22)
Origin IGP, valid, external
Extended Community: RT:4:10010 RT:4:10040 ET:8 Rmac:44:38:39:ff:00:05
Last update: Wed Aug 4 12:17:02 2021
Route [2]:[0]:[48]:[00:00:00:00:00:06]:[32]:[10.10.10.106] VNI 10010/10040
65550 64523
34.34.34.34 from Spine1(swp1) (11.11.11.11)
Origin IGP, valid, external, bestpath-from-AS 65550, best (Older Path)
Extended Community: RT:4:10010 RT:4:10040 ET:8 Rmac:44:38:39:ff:00:05
Last update: Wed Aug 4 12:17:02 2021
// RIB table
cumulus@Leaf5:mgmt:~$ net show route vrf VRF1 ipv4
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
VRF VRF1:
K>* 0.0.0.0/0 [255/8192] unreachable (ICMP unreachable), 2d04h24m
C>* 10.10.10.0/24 is directly connected, vlan10, 2d04h21m
B>* 10.10.10.105/32 [20/0] via 34.34.34.34, vlan40 onlink, weight 1, 05:58:40
B>* 10.10.10.106/32 [20/0] via 34.34.34.34, vlan40 onlink, weight 1, 1d07h40m
C>* 20.20.20.0/24 is directly connected, vlan20, 2d04h21m
This can cause traffic for this prefix to hash towards Leaf3 (which does not have a direct connection to Server6). Let’s take an example of Server3 pinging Server6.
Because this is a same subnet ping, Server3 tries to ARP for the destination directly. Leaf5 responds back because it already has an entry for Server6 in it’s EVPN ARP cache:
cumulus@Leaf5:mgmt:~$ net show evpn arp vni 10010 ip 10.10.10.106
IP: 10.10.10.106
Type: remote
State: active
MAC: 00:00:00:00:00:06
Sync-info: -
Remote VTEP: 34.34.34.34
Local Seq: 0 Remote Seq: 0
Server3 can now send the ICMP request to Leaf5. The destination MAC address is 00:00:00:00:00:06. Leaf5 does a lookup in it’s MAC address table, and sends the packet out with VNI 10010, towards a destination of 34.34.34.34 (the anycast VTEP address, owned by both Leaf3 and Leaf4):
cumulus@Leaf5:mgmt:~$ net show bridge macs 00:00:00:00:00:06
VLAN Master Interface MAC TunnelDest State Flags LastSeen
-------- ------ --------- ----------------- ----------- ----- ------------------ --------
10 bridge vni10 00:00:00:00:00:06 extern_learn 01:20:27
untagged vni10 00:00:00:00:00:06 34.34.34.34 self, extern_learn 01:20:27
A packet capture confirms the L2VNI:
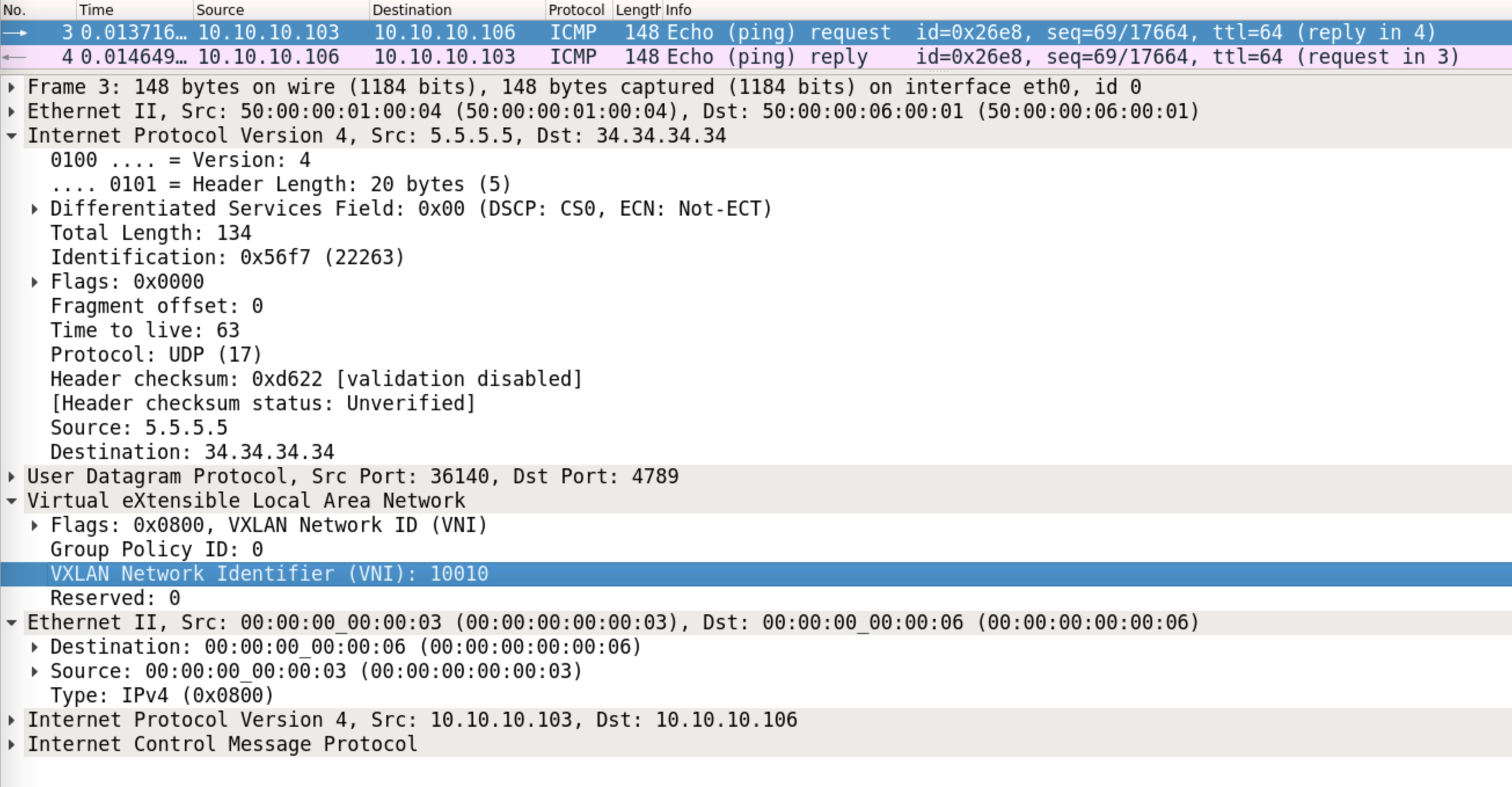
This can be hashed towards Leaf3. Leaf3 simply does a MAC address lookup (for 00:00:00:00:00:06) now, and find’s that is it reachable via the peer-link:
cumulus@Leaf3:mgmt:~$ net show bridge macs 00:00:00:00:00:06
VLAN Master Interface MAC TunnelDest State Flags LastSeen
---- ------ --------- ----------------- ---------- ----- ----- --------
10 bridge peerlink 00:00:00:00:00:06 00:00:53
Thus, visually, the path of the packet in this case would be:
The next big why - why are type-5 EVPN routes sent with the local VTEP address, instead of the anycast VTEP address? It is quite common to see external prefixes advertised via one of the MLAG peers only, and not both. In such cases, you can potentially black hole traffic by advertising these type-5 prefixes with the anycast VTEP address (because traffic may be ECMP’d to the peer which does not have a route to these external prefixes). Of course, this can be fixed by having per VRF iBGP peering between the MLAG peers but it doesn’t scale well and is a lot of administrative overhead.
In general, the ‘advertise-pip’ BGP EVPN option is used for this - the local VTEP IP address is the ‘Primary IP’. Cumulus Linux introduced this in their 4.0 release and it is enabled by default.
However, it needs to be configured in a particular way for it to work. Prior to 4.0, you could use the ‘hwaddress’ option to specify a MAC address for an interface. From 4.0 onward, you need to use the ‘address-virtual’ option to create the common router MAC that is shared between the two MLAG peers. This allows for each MLAG peer to retain it’s unique system MAC and share this common router MAC.
This change is done under the SVI that maps to the L3VNI:
// Leaf3
cumulus@Leaf3:mgmt:~$ net show configuration interface vlan40
interface vlan40
address-virtual 44:38:39:FF:00:05
vlan-id 40
vlan-raw-device bridge
vrf VRF1
// Leaf4
cumulus@Leaf4:mgmt:~$ net show configuration interface vlan40
interface vlan40
address-virtual 44:38:39:FF:00:05
vlan-id 40
vlan-raw-device bridge
vrf VRF1
You should now see the router MAC changed to this common anycast MAC address (general practice is to just set it as the CLAG MAC address), while the system MAC is retained.
// Leaf3
cumulus@Leaf3:mgmt:~$ net show bgp l2vpn evpn vni 10040
VNI: 10040 (known to the kernel)
Type: L3
Tenant VRF: VRF1
RD: 12.12.12.1:3
Originator IP: 34.34.34.34
Advertise-gw-macip : n/a
Advertise-svi-macip : n/a
Advertise-pip: Yes
System-IP: 3.3.3.3
System-MAC: 50:00:00:05:00:05
Router-MAC: 44:38:39:ff:00:05
Import Route Target:
1:10040
2:10040
4:10040
5:10040
Export Route Target:
3:10040
// Leaf4
cumulus@Leaf4:mgmt:~$ net show bgp l2vpn evpn vni 10040
VNI: 10040 (known to the kernel)
Type: L3
Tenant VRF: VRF1
RD: 50.50.50.1:2
Originator IP: 34.34.34.34
Advertise-gw-macip : n/a
Advertise-svi-macip : n/a
Advertise-pip: Yes
System-IP: 4.4.4.4
System-MAC: 50:00:00:06:00:05
Router-MAC: 44:38:39:ff:00:05
Import Route Target:
1:10040
2:10040
3:10040
5:10040
Export Route Target:
4:10040
This gives a lot of good information - it tells you that ‘advertise-pip’ is enabled, what the system IP is, what the system MAC and the router MAC is. Thus, for type-5 prefixes, the system IP and the system MAC are used, and for type-2 prefix (regardless of the host being an orphan host), the router MAC and the anycast VTEP IP address is used.
The type-5 routes are now generated using the system IP and MAC itself.
cumulus@Leaf3:mgmt:~$ net show bgp l2vpn evpn route rd 12.12.12.1:3 prefix 99.99.99.99/32
BGP routing table entry for 12.12.12.1:3:[5]:[0]:[32]:[99.99.99.99]
Paths: (1 available, best #1)
Advertised to non peer-group peers:
Leaf4(peerlink.4094) Spine1(swp1) Spine2(swp2)
Route [5]:[0]:[32]:[99.99.99.99] VNI 10040
12
3.3.3.3 from 0.0.0.0 (3.3.3.3)
Origin IGP, metric 0, valid, sourced, local, bestpath-from-AS 12, best (First path received)
Extended Community: ET:8 RT:3:10040 Rmac:50:00:00:05:00:05
Last update: Tue Aug 3 04:46:12 2021
This is advertised only with the L3VNI. On other VTEPs, this should be installed in the VRF table:
cumulus@Leaf5:mgmt:~$ net show route vrf VRF1 ipv4
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
VRF VRF1:
K>* 0.0.0.0/0 [255/8192] unreachable (ICMP unreachable), 5d00h05m
C>* 10.10.10.0/24 is directly connected, vlan10, 5d00h02m
B>* 10.10.10.105/32 [20/0] via 34.34.34.34, vlan40 onlink, weight 1, 04:16:51
B>* 10.10.10.106/32 [20/0] via 34.34.34.34, vlan40 onlink, weight 1, 04:16:51
C>* 20.20.20.0/24 is directly connected, vlan20, 5d00h02m
B>* 99.99.99.99/32 [20/0] via 3.3.3.3, vlan40 onlink, weight 1, 00:00:01
Before we wrap this up, it is important to talk about some failure scenarios with MLAG. An important design consideration (and we’ll see this more prominently when we talk about Ethernet Segments in EVPN), is that losing a downlink (towards the server itself) has no control-plane implications. There is absolutely no control-plane convergence because of this - it is purely a data plane forwarding change.
For example, say Leaf3s interface going to Server5 goes down. Traffic can still be hashed towards Leaf3, destined for Server5. It would just be forwarded over the peer-link. This is why capacity planning of the peer-link is equally important.
A second failure scenario to consider is what would happen if all fabric links go down. So, for example, Leaf3 loses all its spine facing links and the packet from Server5 (destined to Server2) is hashed to Leaf3.
This is where the iBGP peering is useful. Prior to this event, the route is received via the spines, and via the iBGP peering to the MLAG peer.
cumulus@Leaf3:mgmt:~$ net show bgp l2vpn evpn route rd 5.5.5.5:2 mac 00:00:00:00:00:02 ip 20.20.20.102
BGP routing table entry for 5.5.5.5:2:[2]:[0]:[48]:[00:00:00:00:00:02]:[32]:[20.20.20.102]
Paths: (3 available, best #2)
Advertised to non peer-group peers:
Leaf4(peerlink.4094) Spine1(swp1) Spine2(swp2)
Route [2]:[0]:[48]:[00:00:00:00:00:02]:[32]:[20.20.20.102] VNI 10020/10040
65550 64525
5.5.5.5 from Leaf4(peerlink.4094) (4.4.4.4)
Origin IGP, localpref 100, valid, internal
Extended Community: RT:5:10020 RT:5:10040 ET:8 Rmac:00:20:00:20:00:20
Last update: Sat Aug 7 08:18:29 2021
Route [2]:[0]:[48]:[00:00:00:00:00:02]:[32]:[20.20.20.102] VNI 10020/10040
65550 64525
5.5.5.5 from Spine1(swp1) (11.11.11.11)
Origin IGP, valid, external, bestpath-from-AS 65550, best (Older Path)
Extended Community: RT:5:10020 RT:5:10040 ET:8 Rmac:00:20:00:20:00:20
Last update: Sat Aug 7 03:51:08 2021
Route [2]:[0]:[48]:[00:00:00:00:00:02]:[32]:[20.20.20.102] VNI 10020/10040
65550 64525
5.5.5.5 from Spine2(swp2) (22.22.22.22)
Origin IGP, valid, external
Extended Community: RT:5:10020 RT:5:10040 ET:8 Rmac:00:20:00:20:00:20
Last update: Sat Aug 7 03:51:08 2021
After the link down event (and route withdrawals), the traffic is simply routed via the peer-link. If the iBGP peering was missing, traffic would be blackholed on Leaf3.
In the next post, we’ll look at how Ethernet Segment based EVPN multi-homing acts as an alternative to MLAGs.