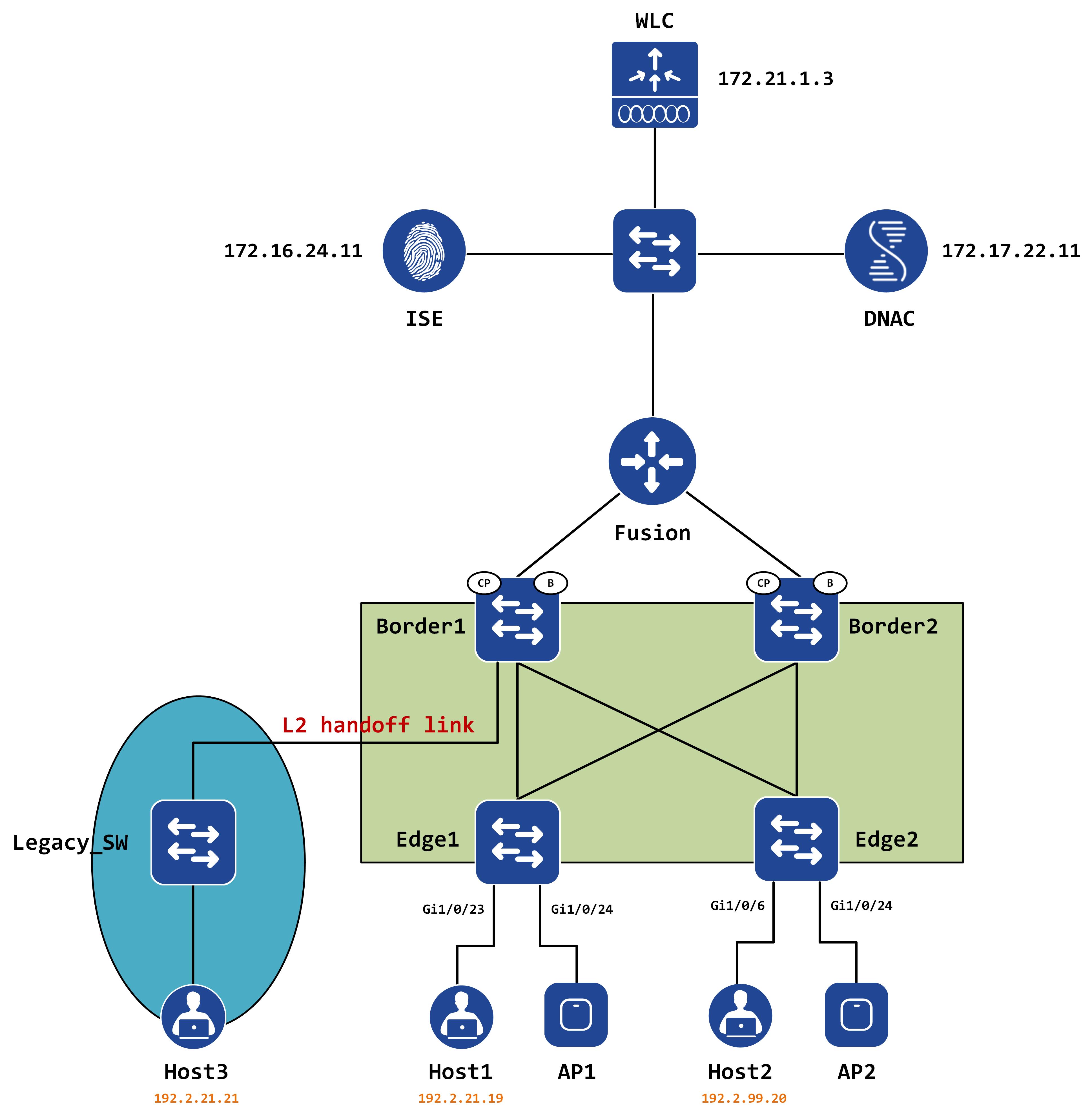
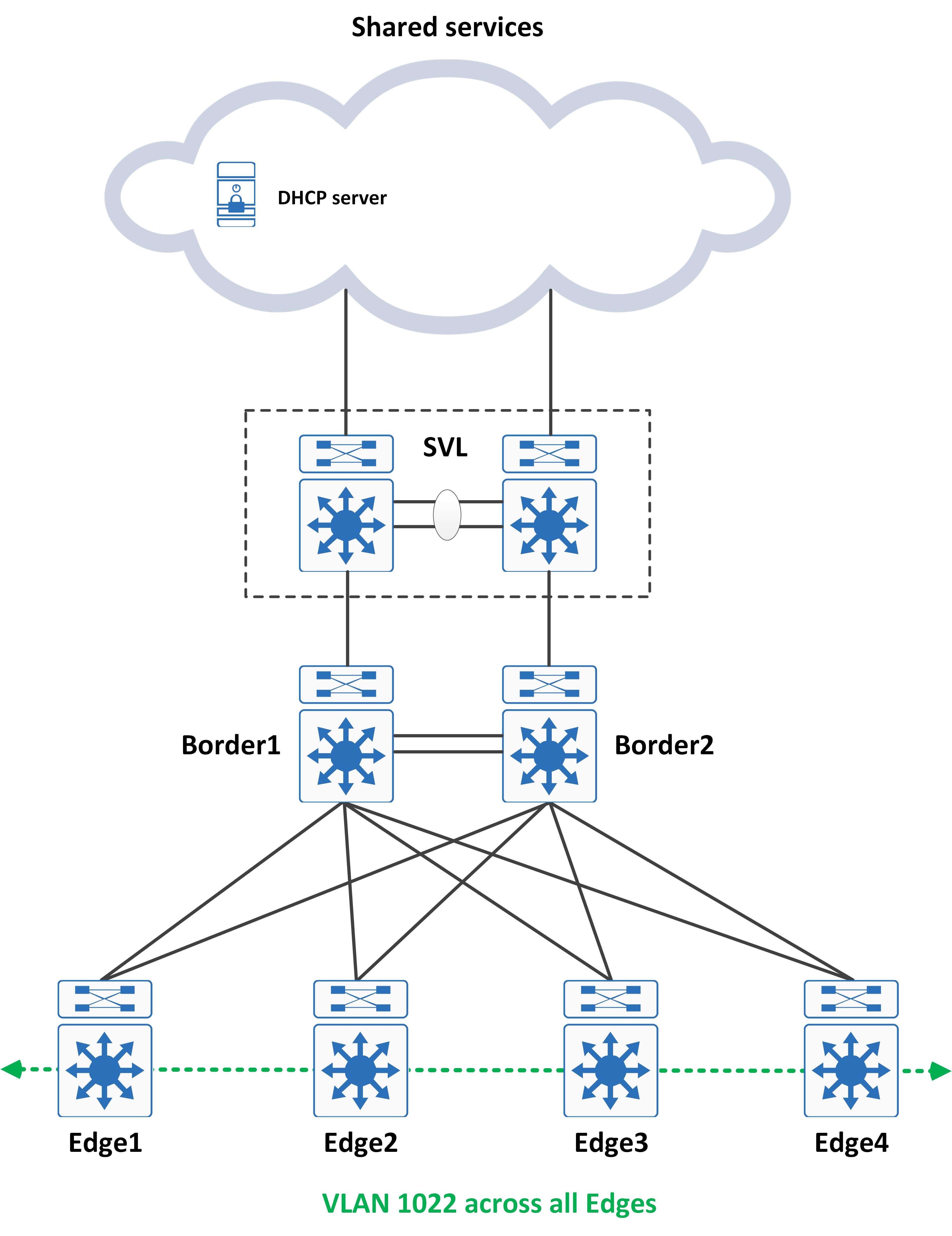
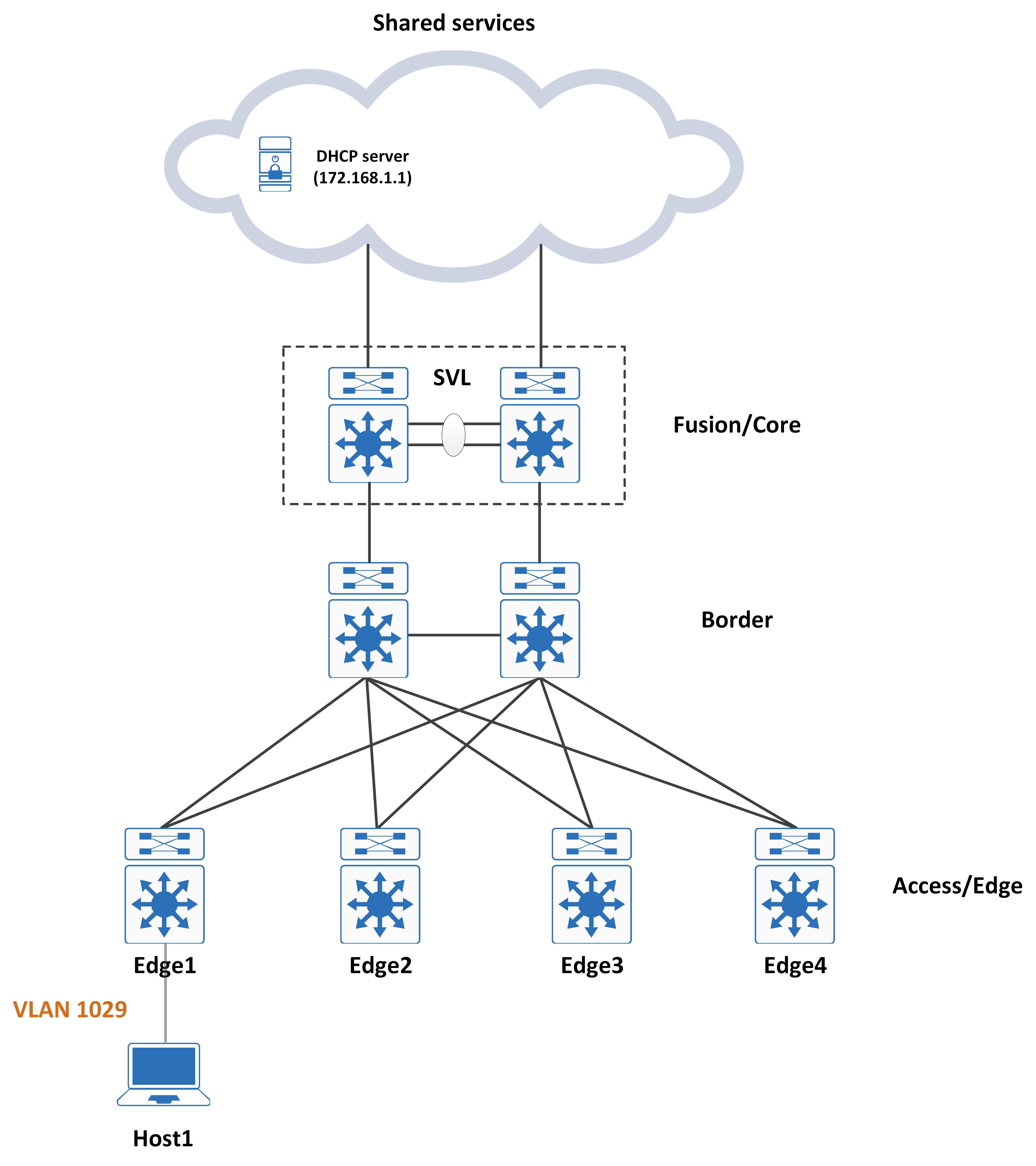
Looking at the some of the configuration that is automatically pushed from DNAC, you should spot some very interesting things in there. This post aims to demystify these and help the reader understand why these were needed in the first place, hopefully giving you a better understanding of how the SDA fabric is built.
Remember that in SD-Access, we do not use vanilla LISP. To achieve macro segmentation, multi-instance LISP (VRF-aware LISP) is used. However, this poses a problem for DHCP. Consider the following topology for this (this topology is also a simple example of SD-Access design):
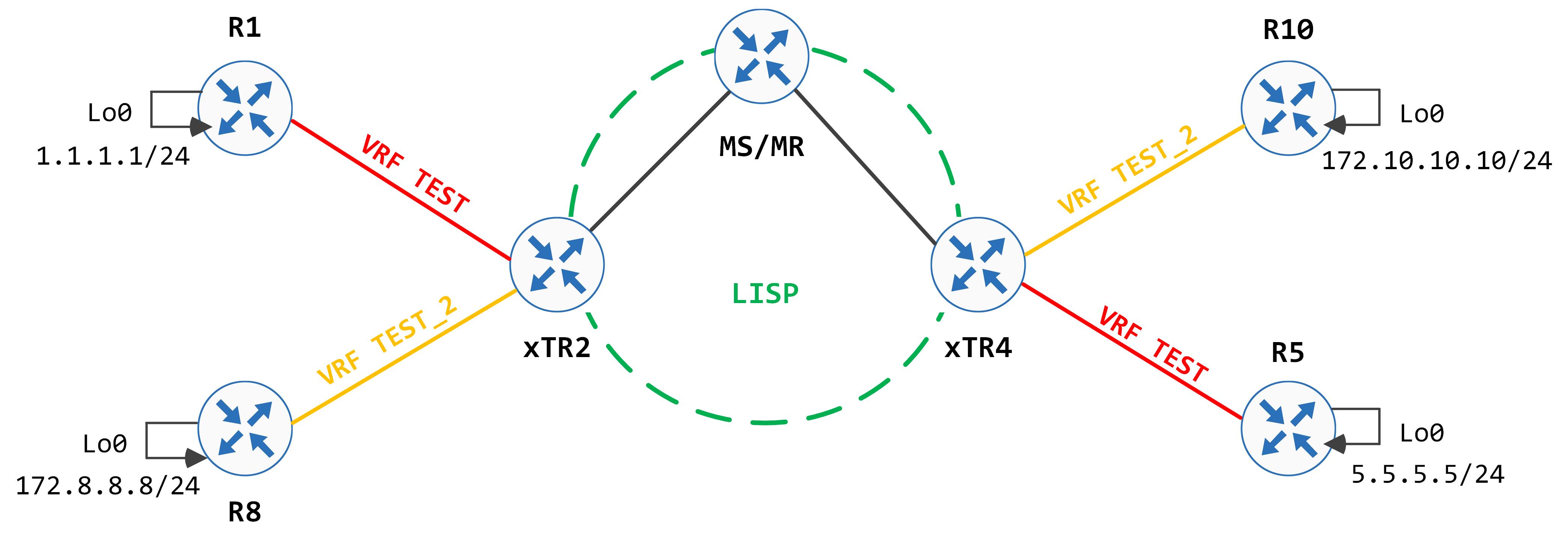
We're slowly getting closer to the true implementation of LISP in Cisco's SD-Access. LISP has the capability of being VRF-aware - this is achieved via multi-instance LISP.
The idea is fairly simple - you have multiple instances of LISP (mapped to corresponding VRFs) - all your LISP tables are now maintained per instance.
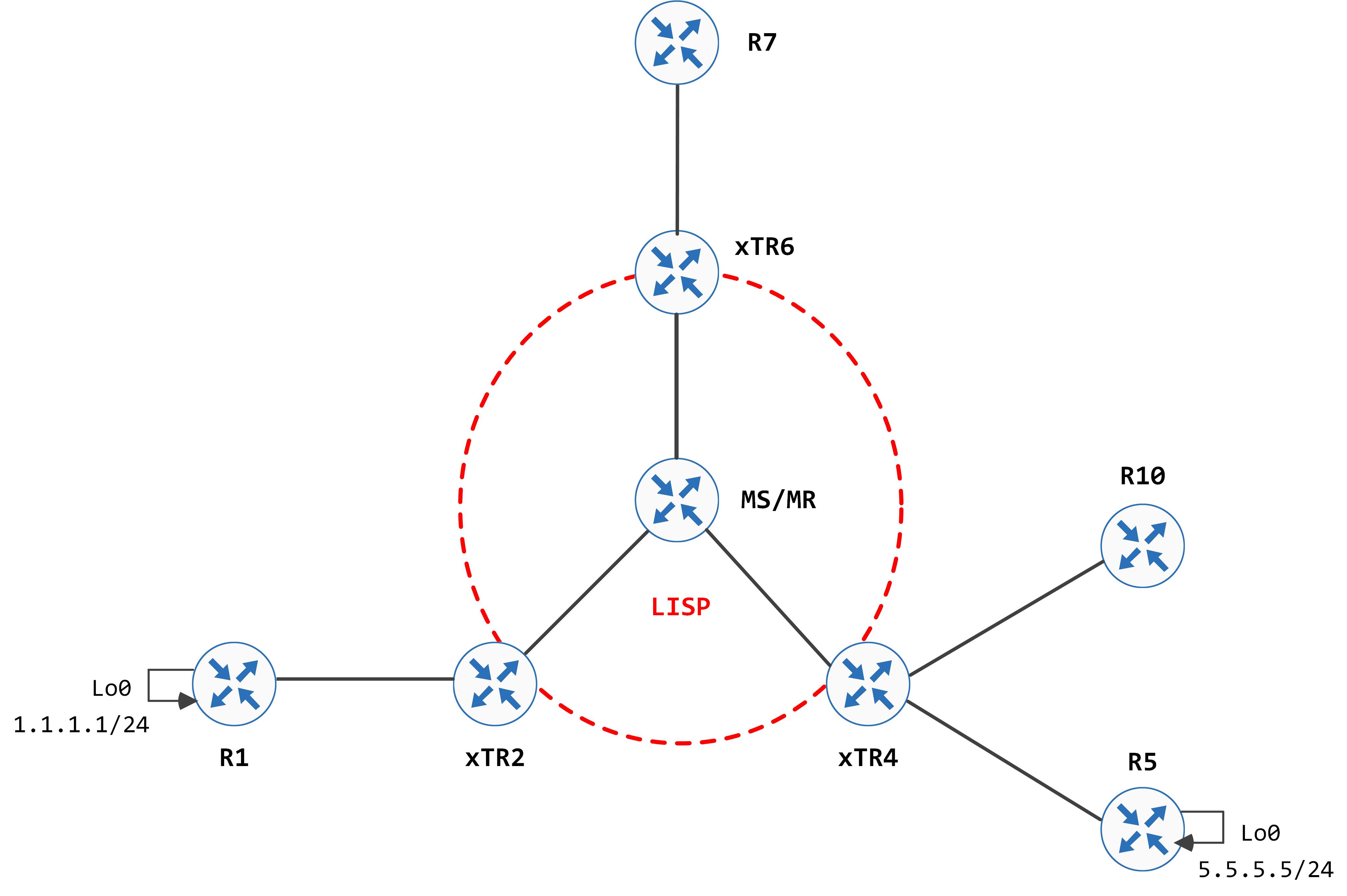
We start this post with the assumption that a host mobility event has occurred (see previous post for details on host mobility) and that the EID 1.1.1.1/24 is moved from behind xTR2 to behind xTR6.
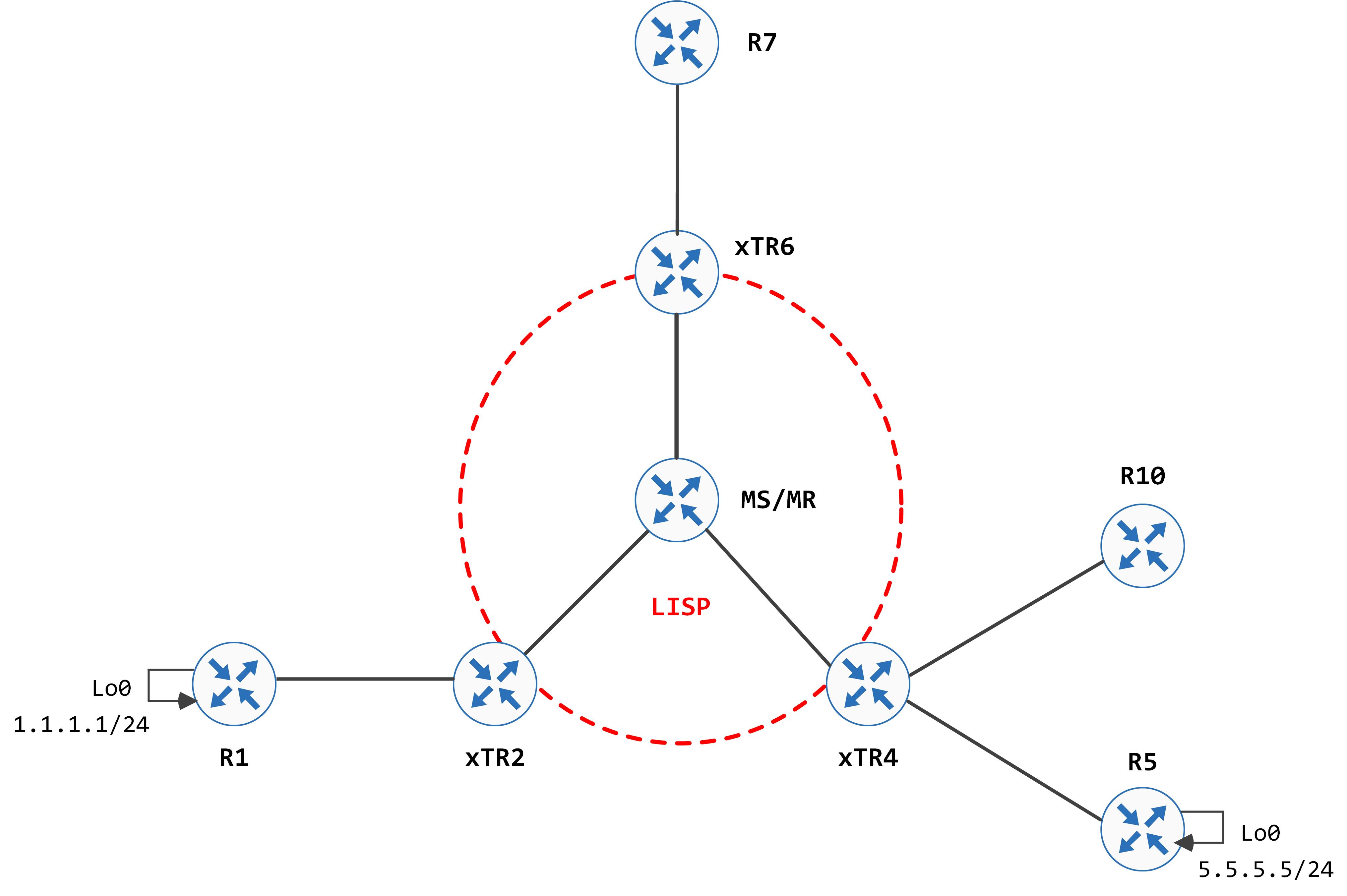
Continuing on from the previous post, we take a look at actual host mobility events and how the LISP infrastructure facilitates this. Our goal for this post is to have the simulated host (1.1.1.1) move from behind xTR2 to behind xTR4 (simulated via R10). A working assumption used in the post is that there is no active traffic destined for the host that is moving (we will look at this in the SMR post).
The topology is a slightly modified version of what we used in the last post:
One of the most important characteristics of LISP is the mobility it offers - the next few posts aim at helping understand how this functionality is achieved, starting with dynamic EIDs.
We will continue using the same topology as before, with some minor changes to the xTRs. xTR6 is now another xTR and not a PxTR.
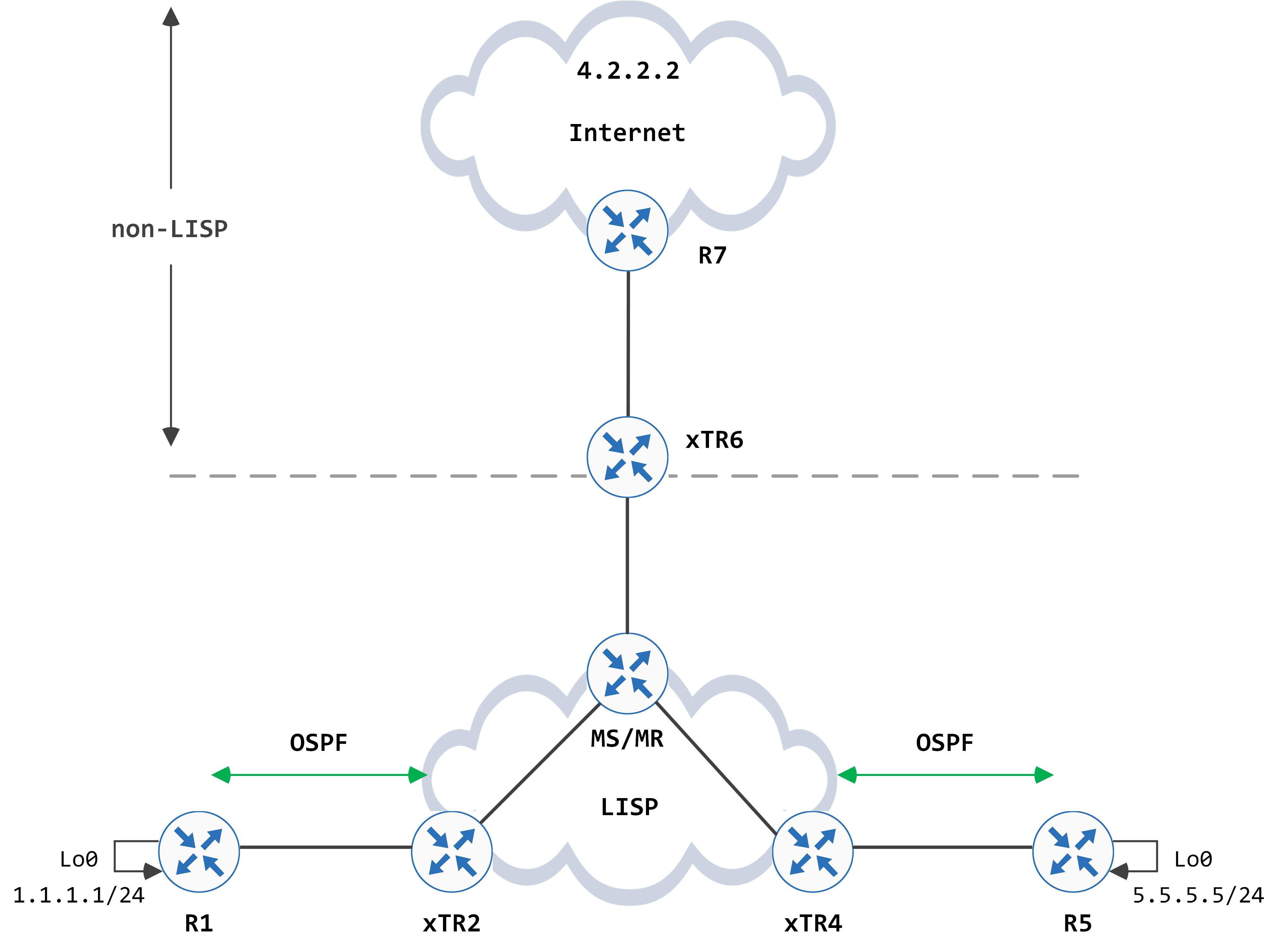
Understanding how a LISP site talks to a non-LISP site (and vice versa) is very crucial to LISP and the bigger picture that we're building towards - SDA.
The topology that we'll work with is a slightly modified version of what we had before - another router has been added that will facilitate conversation between LISP and non-LISP:
Now that we've covered this new routing paradigm that LISP introduces in the previous post and understood some commonly used terms, we will move on to basic LISP operations.
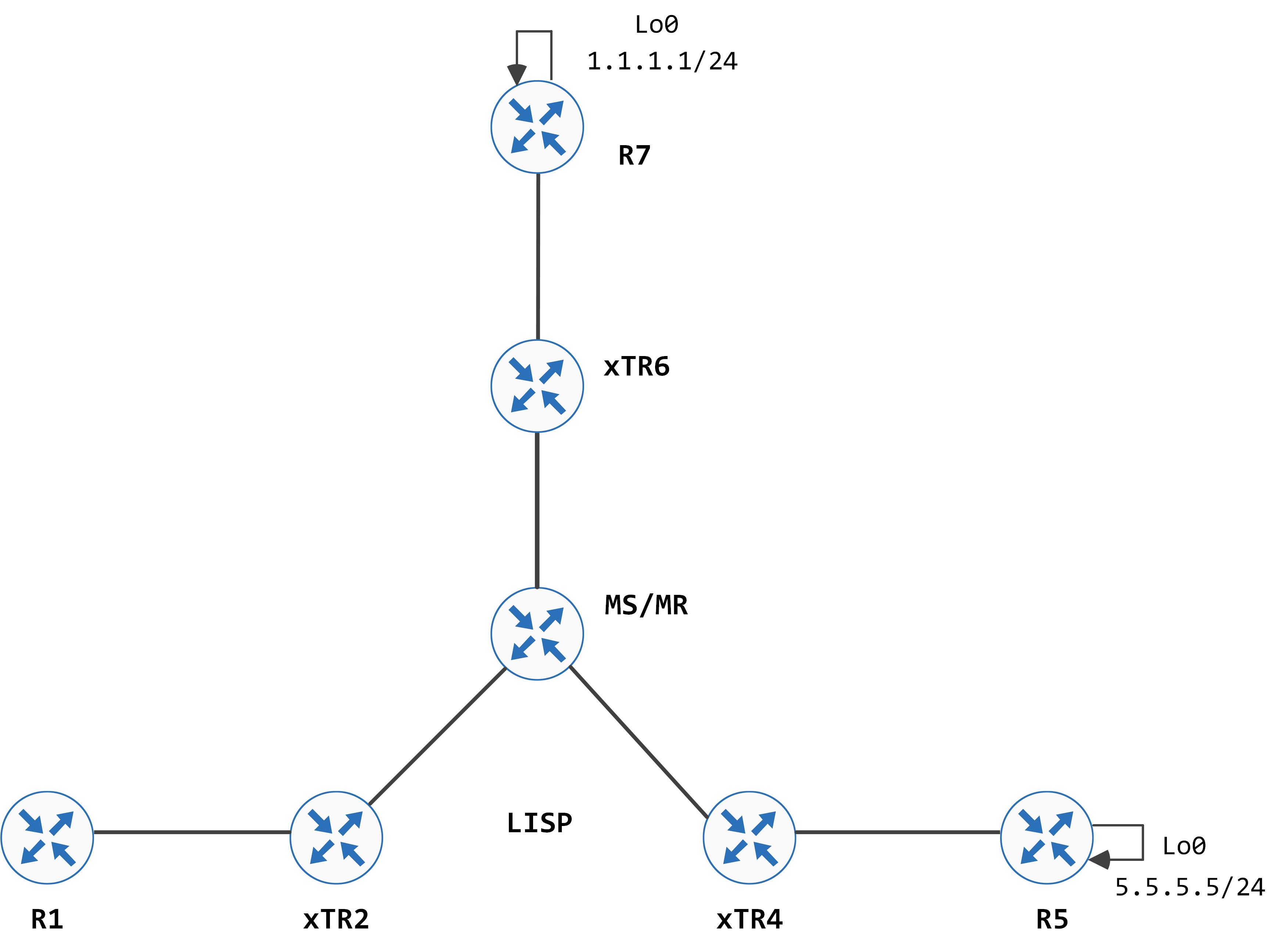
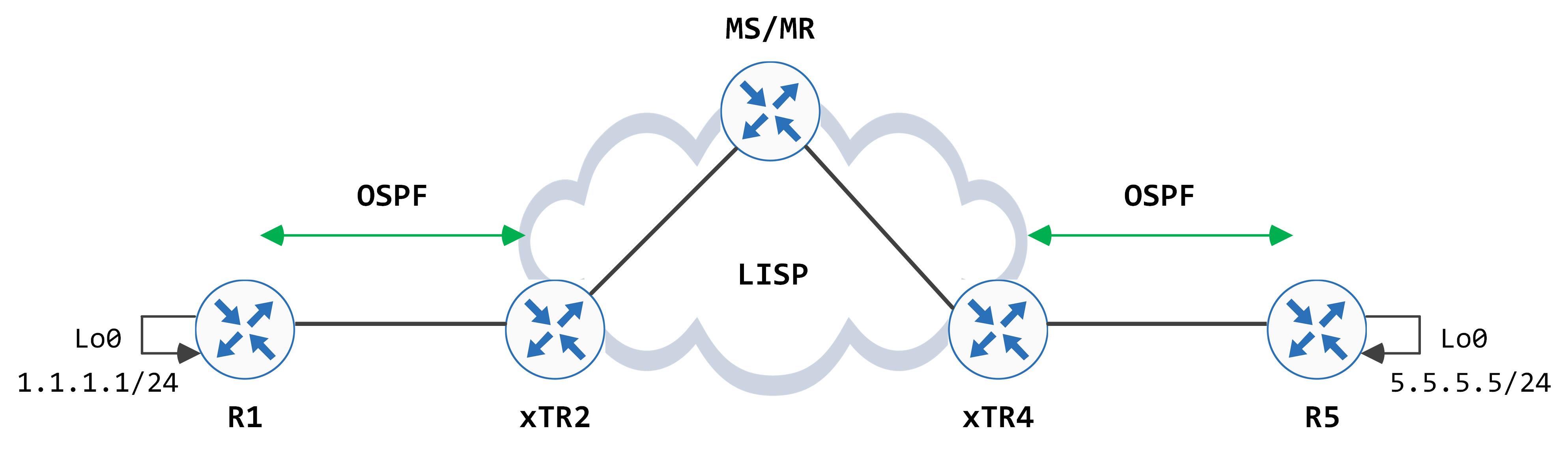
The topology that we will be using is the following:
This is a new series that will cover Cisco's Software Defined Access architecture/solution over time. There are several moving pieces to this - in this post, we're going to start with a key component, which is LISP.
This is a new series that will cover Cisco's Software Defined Access architecture/solution over time. There are several moving pieces to this - we're going to start with a key component, which is LISP.
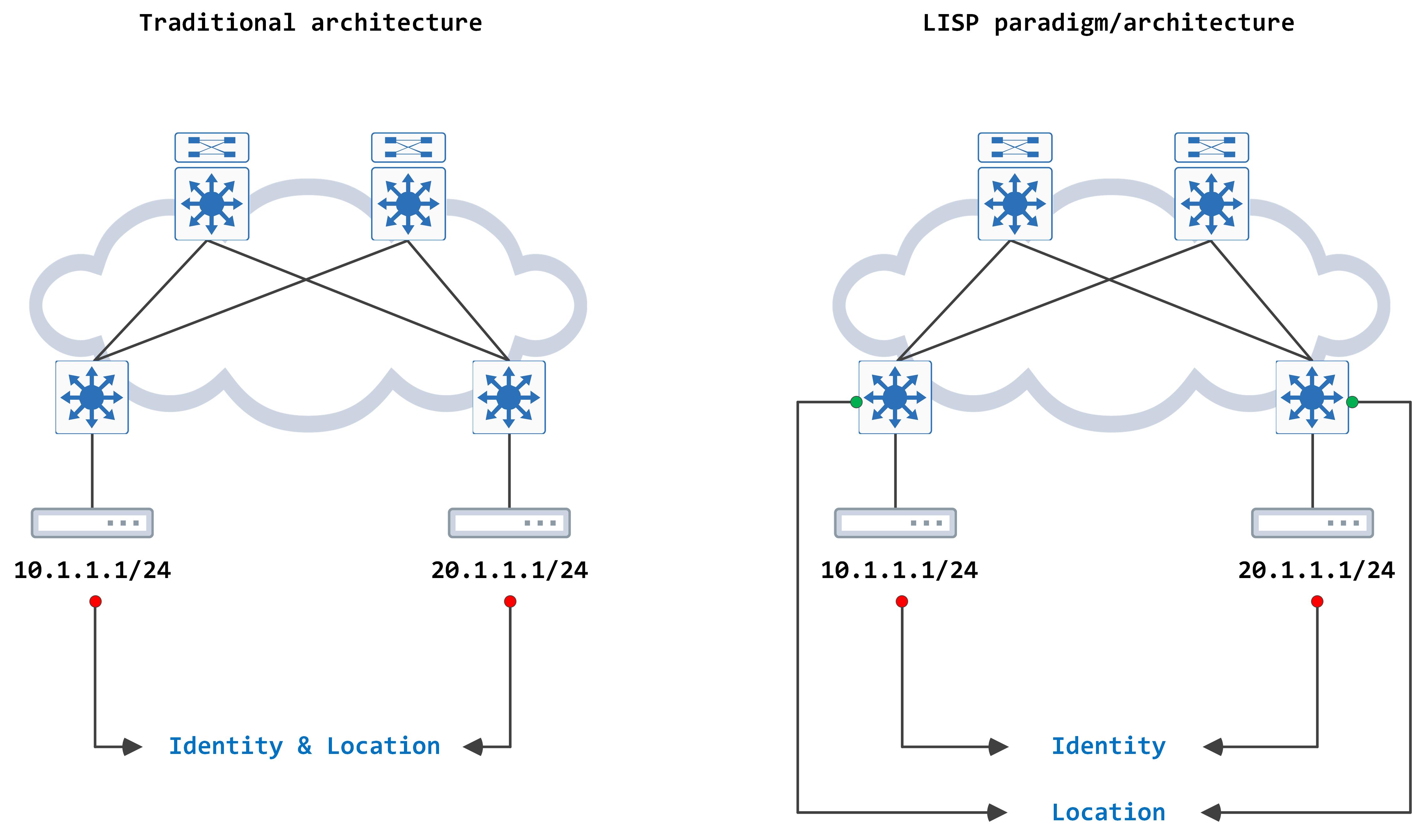
LISP stands for Locator/ID Separation protocol. Let's quickly revisit how endpoints are/were identified - with a simple IP address (IPv4/IPv6, what have you). The IP address was both the location and the identity of the endpoint. LISP (which serves as a routing architecture), aims to decouple the identity of an endpoint from its location.
The IP address continues to be the identity of the endpoint however, its location is now advertised as a separate entity (or address space) as well.
A simple visual comparison helps understand this better: